Appliance Manager provides current and historical views of the state and the performance of a storage server. This includes CPU usage, disk and network throughput, and many other metrics. It also allows you to view connected clients and determine how each of these contribute to the current workload.
This chapter does not describe all of the details of each Appliance Manager monitoring screen, because most screens are quite straightforward. Instead, it attempts to explain why the displayed information matters and how it can be sensibly interpreted.
This chapter discusses the following:
Figure 4-1 shows the top-level Monitoring screen.
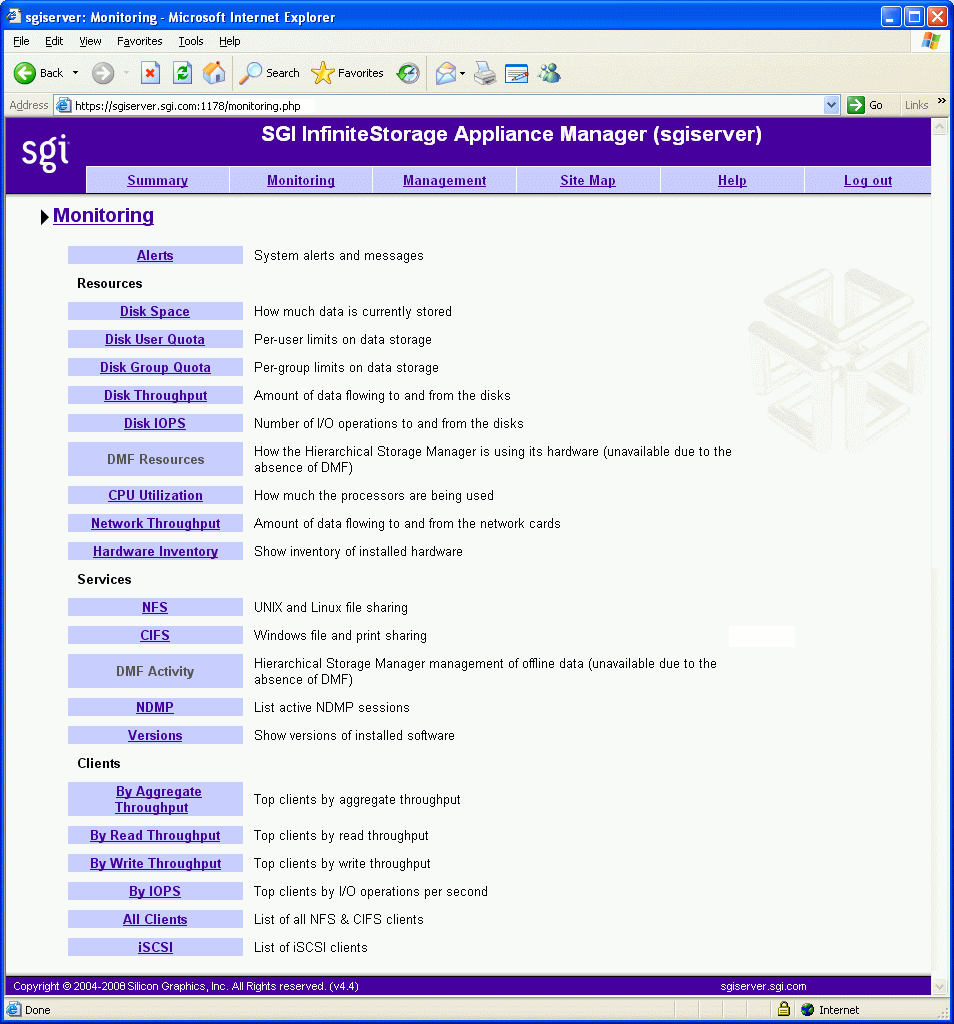
The information provided by Appliance Manager can be roughly broken down into “who” and “how much.” Appliance Manager continuously gathers performance metrics and stores them in archives in /var/lib/appman/archives. Each month, a data reduction process is performed on the metric gathered for the month. This reduces the size of the archives while retaining a consistent amount of information.
Although the size of metric archives has a bounded maximum, this can still be quite large depending on the configuration of the server and how many clients access it. For example, a server with a large number of filesystems could generate up to 100 Mbytes of archives per day. You should initially allow around 2 Gbytes of space for archive storage and monitor the actual usage for the first few weeks of operation.
| Note: Appliance
Manager uses the International Electrotechnical Commission's International
Standard names and symbols for binary multiples of units. In particular,
this means that 1 MiB/s is 220 = 1048576 Bytes
per second. For more information on this standard, see the National Institute
of Standards & Technology information about prefixes for binary multiples
at:
http://physics.nist.gov/cuu/Units/binary.html |
Appliance Manager distinguishes between current and historic time. Current metrics are either drawn live from the server or are taken from the last few minutes of the metric archives. Historic metrics are taken exclusively from the metric archives. Appliance Manager is able to display this historical information for three time periods:
Last hour
Last day (the previous 24 hours)
Last month (the previous 30 days)
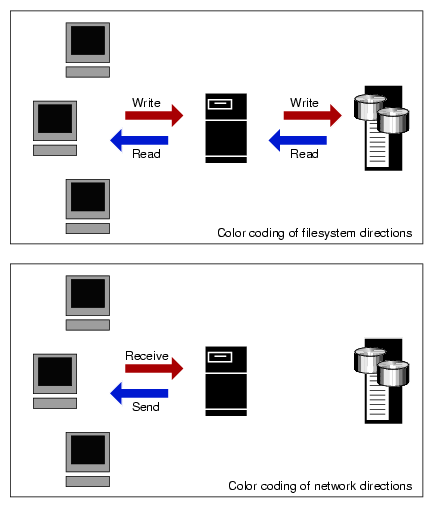
Within bar graphs, Appliance Manager uses color-coding to display the direction of data flow:
Figure 4-2 describes how Appliance Manager color-codes the direction of data flow graphs. For an example of the result in a graph, see Figure 4-3.
Appliance Manager provides a Summary menu selection at the top of the screen. This screen displays the following on a per-node basis:
CXFS filesystem and node status (For details, see “CXFS”):
If all CXFS filesystems are stable (or if no filesystems exist), the Filesystems indicator will be green, and it will say Stable
If all cluster nodes are stable, the Nodes indicator will be green it will say Stable
If any of the filesystems or nodes are inactive or in a transient state (such as mounting filesystems), the indicators will be red and appropriate status text will be displayed
The number of NFS, CIFS, and iSCSI clients (if iSCSI targets have been created)
The screen displays ticks along the status bars that represent the average value over the past day or hour, rather than the immediate value that is shown by the graph.
You can drill down to more detailed status by clicking the headings to the left of the graphs.
Click History to view the historical status of a parameter.
Figure 4-3 shows an example Summary screen.
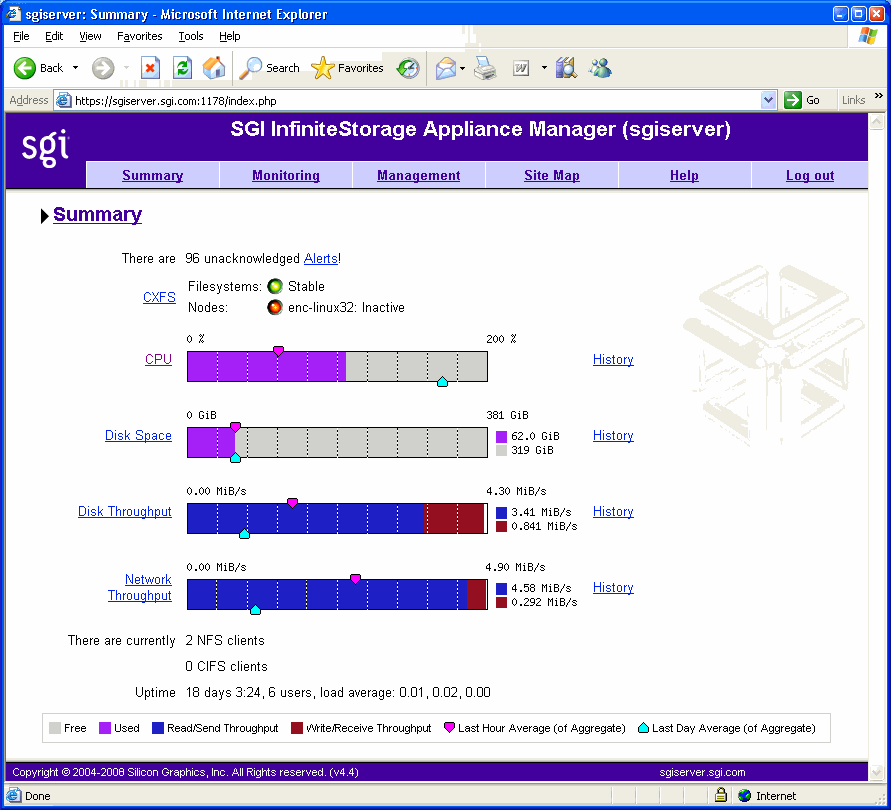
In Figure 4-3, the bar graph for Disk Throughput shows 3.41 MiB/s of data read/sent (the blue part of the graph) and 0.841 MiB/s of data written/received (the red part of the graph). If you were sending and receiving data at the same rate, there would be equal amounts of red and blue in the graph. For more information, see Figure 4-2.
The Alerts screen displays messages from the system logs. These provide informative messages, notifications of unusual events, and error conditions.
Only unacknowledged alerts are displayed unless you click Show Acknowledged. You must log in in order to acknowledge alerts.
After a period of time, alerts are archived and will not be redisplayed. Acknowledged alerts are archived after 2 days and unacknowledged alerts are archived after 7 days. The /var/lib/appman/alerts/archive file contains all the archived alert messages.
Appliance Manager contains a separate screen to display the utilization of each resource.
The following sections provide details about the resources:
Where multiple physical resources are bonded into a single logical resource (for example, load-balanced NICs and RAID volumes in a filesystem), Appliance Manager shows the structure of the aggregated resource, and (where possible) shows metrics for both the aggregate and the component resources.
The Disk Space screen shows the GiB used on each filesystem. If the amount of disk space appears low on a filesystem on which disk quotas are enabled, you can use the Disk User Quota screen to find out who is using the most disk space.
Disk user/group quotas provide limits on the number of files and the amount of disk space a user/group is allowed to consume on each filesystem. A side effect of this is that they make it possible to see how much each user/group is currently consuming.
Because quotas are applied on a per-filesystem basis, the limits reported in the All Filesystems screen are not additive. This means that if a user/group has a 500-MiB disk space limit on filesystem A and a 500-MiB limit on filesystem B, the user/group cannot store a 1-GiB file because there is no single filesystem with a large-enough space allowance.
However the current usage shown in the used column on the All Filesystems screen is additive, so you can use this screen to determine the user/groups who are currently consuming the most disk space. The All Filesystems screen highlights user/groups who have exceeded the quota on any filesystem on which they have been allocated a quota.
| Note: Users/groups that do not have quotas explicitly assigned to them are not listed in the monitoring pages. |
Disk operations occur when the result of a file operation is committed to disk. The most common types of disk operation are data reads and writes, but in some types of workload, metadata operations can be significant. Metadata operations include the following:
Truncating and removing files
Looking up filenames
Determining the size and types of files
Disk operations are measured in I/O per second (IOPS).
Disk throughput is the amount of data that is transferred to and from the disks. This is predominantly the result of reading and writing data.
The Disk Throughput and Disk IOPS screens display a bar graph for each active filesystem. For RAID filesystems, a separate graph is displayed for each volume element.
| Note: Users of versions of Appliance Manager prior to 4.1 should note that the IOPS shown for the same workload may be lower now. This indicates a more accurate count, not a decrease in performance. There may be issues if upgrading from 4.0; users may lose all of their history because the graph metrics are now different. |
If the cache hit rate is low and the network throughput is high, the disk throughput should be high. Usually, the disk throughput would be steady somewhere a little under the maximum bandwidth of the disk subsystem. If the disk throughput is consistently too high relative to the network throughput, this might indicate that the server has too little memory for the workload.
Under heavy loads, a storage server must be able to sustain a high rate of disk operations. You can use the disk operations metrics in conjunction with other metrics to determine the characteristics of a workload so that you can tune the server can be tuned. For example, a high utilization of NICs but few IOPS could indicate that a workload is coming straight from the cache. A large number of IOPS but low throughput (either disk or network) indicates a metadata-dominated load. You can determine the contributing operations or clients from the NFS screen, CIFS screen, and the various screens under the Clients category.
The DMF Resources screens show how DMF is using its hardware, as described in the following sections:
For information about troubleshooting, see “DMF Error Messages”. For information on how Appliance Manager displays user-generated DMF activity, see “DMF Activity”.
Note: The DMF Filesystems and
Caches pages are updated at infrequent intervals by those
DMF programs that scan the filesystem inodes:
|
The following displays the tape library slot usage, which is the number of slots used by DMF, other applications, or vacant):
Monitoring -> Resources -> DMF -> Tape Libraries
The Tape Libraries screen is available only if the OpenVault tape subsystem is in use. This screen is unavailable if you are using Tape Management Facility (TMF). (You must choose a single method for handling tapes, either OpenVault or TMF.)
The following shows information about tape drives:
Monitoring -> Resources -> DMF -> Tape Drives
The Tape Drives screen provides information for each tape drive concerning its current state:
When the drive is in use, it also shows the following:
Activity (such as waiting)
Purpose (such as recall)
Details of the tape volume (such as volume name)
| Note: This information is available only for DMF's tapes. Any other use, such as filesystem backups or direct tape use by users, is not shown; any such drives appear to be idle on this screen. |
This screen also includes a link to the Reservation Delay History screen, which indicates when demand for tape drives exceeds the number available. This is purely a relative indication, to be compared visually with the equivalent indicator at other times; it has no useful numerical value.
The following shows the number of tape volumes in various states according to volume group (VG):
Monitoring -> Resources -> DMF -> Tape Volumes
Those volume groups that share an allocation group are shown together inside a box that indicates the grouping.
Because of their normally large number, full volumes are only shown numerically. Those in other states (such as empty) are shown graphically. History links show trends over time.
The following shows the proportions of files on DMF-managed filesystems that are migrated and not migrated:
Monitoring -> Resources -> DMF -> Filesystems
The screen also displays the amount of offline data related to the filesystems and the over-subscription ratios (which are typically in the range of 10:1 to 1000:1, although they vary considerably from site to site). As this is being viewed from the filesystem perspective, the fact that migrated files may have more than one copy on the back-end media is not considered. That is, this is a measure of data that could be on disk but is not at the time, rather than a measure of the amount of back-end media being used.
The data presented in the graph is gathered periodically by DMF. The time at which this information was gathered is displayed at the top of the page. The default configuration is to update this information once daily (at 12:10am). To change this default, use the following menu selection:
Management -> Resources -> DMF -> Configuration -> Maintenance Tasks -> daemon_tasks
The following shows Disk Cache Manager (DCM) disk caches:
Monitoring -> Resources -> DMF -> Caches
DCM disk caches have similar issues to filesystems with regard to the frequency of updates as described in “DMF-Managed Filesystems”.
Dual-resident refers to cache files that have already been copied to back-end tape and can therefore be quickly removed from the cache if it starts filling. Non-dual-resident files would have tape copies made before they could be removed, which is much slower.
This section describes problems you may encounter when monitoring DMF with Appliance Manager.
This screen requires statistics from DMF that are unavailable; check that DMF is running, including the "pmdadmf2"process. Make sure the DMF "EXPORT_METRICS" configuration parameter is enabled. |
This message indicates that DMF is idle. When this occurs, perform the following procedure:
Check the version of DMF by running the dmversion command. It should report version 3.4.0.0 or later.
Check that the EXPORT_METRICS on line has been added to /etc/dmf/dmf.conf after the TYPE base line.
Run dmcheck to search the DMF configuration file for syntactic errors.
Check that DMF has been restarted after the change to /etc/dmf/dmf.conf was made in step 2.
Check that the data is being exported by DMF by running the following command:
# dmarenadump -v
If it is not, run the following commands as root to restart DMF, PCP, and Appliance Manager:
# cd /dmf/spool # or equivalent at your site # rm base/arena # /etc/init.d/dmf restart # /etc/init.d/pcp stop # /etc/init.d/pcp start # /etc/init.d/appman restart # if necessary
Check that the data is passing through PCP by running the following command:
# pminfo -f dmf2
If it is not, run the following commands as root to remove and reinstall the PCP performance metrics domain agents and restart Appliance Manager:
# cd /var/lib/pcp/pmdas/dmf2 # ./Remove # ./Install # /etc/init.d/appman restart
No OpenVault-controlled library found. |
This indicates that OpenVault is not running. Run the following command to verify that the ov_stat command is available:
# ls -lL /usr/bin/ov_stat -rws--x--x 1 root sys 322304 Jul 22 2005 /usr/bin/ov_stat |
If the file permissions are not -rws--x--x as shown above, run the following command to change the permissions:
# chmod 4711 /usr/bin/ov_stat |
Serving files places demands on the storage server CPU as well as the I/O subsystem. The CPU helps with copying data to and from disks, calculating checksums, and other tasks. Table 4-1 shows the CPU metrics that Appliance Manager reports.
Table 4-1. CPU Metrics Reported by Appliance Manager
CPU Metric | Description |
|---|---|
Time when a CPU was forced to do nothing while waiting for an event to occur. Typical causes of wait time are filesystem I/O and memory swapping. | |
Time the CPU spent processing requests from I/O devices. In a storage server context, these are almost exclusively generated by disk operations or network packets and by switching between processes. | |
Time the CPU spent executing kernel code. This is usually dominated by NFS file serving and accessing data from disks. | |
Time when the CPU is devoted to running ordinary programs. The biggest consumers of user time in a storage server would usually be the CIFS server, HTTP server, or FTP server. |
CPU time is displayed as a percentage, where 100% is the total time available from a single CPU. This means that for an 8-CPU server, the total available CPU time is 800%.
In general, NFS workloads consume more system time, whereas CIFS, HTTP, and FTP workloads consume more user time. The Appliance Manager performance monitoring infrastructure consumes only a small amount of user time.
The most useful problem indicator is consistently having little or no idle time. This can mean that the server is underpowered compared to the workload that is expected of it.
The Network Throughput screen displays the amount of data transferred through each network interface card (NIC).
If an interface is load-balanced, Appliance Manager displays throughput for both the bonded interface and its constituent interfaces.
| Note: The throughput displayed is total network throughput (which includes protocol headers), so real data transfer will be somewhat lower than this value. The Services category screens show the amount of real data transferred from a variety of perspectives. |
A service is a task that is performed by the storage server. While the primary service is fileserving, Appliance Manager breaks this down by the different methods of accessing the server. The services known to Appliance Manager are NFS, CIFS, CXFS, DMF, and NDMP. This screen also provides access to the software versions installed.
This section discusses the following screens available under the Services category:
| Note: The NFS screen is available only if SGI Enhanced NFS is installed. |
NFS traffic is a major contributor to storage server utilization. NFS services report statistics aggregated across all exports/shares as well as statistics for each export/share.
Table 4-2 describes the statistics reported by both the NFS and CIFS screens. Table 4-3 and Table 4-6 describe additional information that is reported.
NFS services gather like-operations into a smaller number of operation classes. Table 4-4 summarizes these classes. (The NFS operation statistics measure classes of NFS protocol operations sent by clients.)
Table 4-2. Statistics Reported by NFS and CIFS Screens
Graph | Description |
|---|---|
Current incoming and outgoing traffic for the export/share (the NFS service Throughput graph includes all types of operations, whereas the CIFS graph only shows actual data transfer) | |
Operations by Type | |
Read Block Sizes | |
Write Block Sizes |
Table 4-3. Additional Information Reported by the NFS Screen
Category | Description |
|---|---|
IOPS | |
Number of operations falling into each service time band as tracked by the NFS server for each operation |
Table 4-4. NFS Operation Classes
Class | Description |
|---|---|
File accessibility tests; checks whether a client can open a particular file | |
Commit request; requests that the server flush asynchronously written data to stable storage | |
Filesystem statistics and information requests, pathconf calls, and service availability tests | |
File attribute retrieval operations | |
New file or directory creation, hard and symbolic link creation, file renaming, and device file creation operations | |
General lock operations not covered by other classes | |
Number of lock granting operations | |
Number of export/share reservation operations | |
Operations that result in filename translations; that is, operations that are applied to a filename rather than to a file handle, such as open | |
File read operations and symbolic link resolution operations | |
Directory entry listing operations | |
Extended directory entry listing operations; returns the attributes of the directory entries as well as their names | |
File deletion operations | |
File attribute setting operations, which include file truncations and changing permissions and ownership | |
Asynchronous writes; the written data may be cached and scheduled for writing at a later time | |
Synchronous write; these do not complete until the data is written to stable storage | |
Operations that manipulate XFS extended attributes |
| Note: The CIFS screen is available only if the SGI Samba packages are installed. |
CIFS traffic is a major contributor to storage server utilization. CIFS services report statistics aggregated across all exports/shares as well as statistics for each export/share.
Table 4-2 describes the statistics reported by both the NFS and CIFS screens.
CIFS services gather like operations into a smaller number of operation classes. While these classes are largely similar, there are some differences. Table 4-5 summarizes these classes.
| Note: Clients can perform file operations in a variety of different ways, which can result in similar logical operations being recorded as differing sets of CIFS operations depending on the application. |
Table 4-5. CIFS Operation Classes
Table 4-6. Additional Information Reported by the CIFS Screen
Category | Description |
|---|---|
IOPS | |
Number of SMB operations falling into each service time band |
The CXFS screen reports the status of CXFS filesystems and cluster nodes.
Filesystem information:
Filesystem name.
A Usage bar that shows the amount of disk space used on the filesystem. The numbers to the right of the bar show used space and filesystem size in gigabytes.
Stable indicator, which is either green if the current state of the system matches the expected state of the system or red if it does not. For example, a filesystem is considered stable if it has been successfully mounted by all nodes that are capable of mounting it. If one or more nodes are currently trying to mount a filesystem, its stable indicator will be red and the Status text will be similar to hostname: trying to mount. After all nodes have mounted the filesystem, the indicator will be green.
The most common Status states for filesystems include:
Mounted : All enabled nodes have mounted the filesystem
Unmounted: All nodes have unmounted the filesystem
Node information:
Hostname.
Node type, which is either server for the metadata server or client for a client-only node.[10]
Cell ID, which is a number associated with a node that is allocated when a node is added into the cluster definition. The first node in the cluster has cell ID of 0, and each subsequent node added gets the next available (incremental) cell ID. If a node is removed from the cluster definition, its former cell ID becomes available.
Connected indicator, which is one of the following colors:
Green if the node is physically plugged in, turned on, and accessible via the private network and Fibre Channel switch
Red if the node is not accessible
Gray if the node has been intentionally disabled by the administrator
Stable indicator, which is one of the following colors:
Green if the node has joined the cluster and mounted the clustered filesystems
Red if the node has not joined the cluster and mounted the filesystems
Gray if the node has been intentionally disabled by the administrator
When a node comes online, the Connected indicator should always be green, with the Stable indicator red while the node is establishing membership, probing XVM volumes, and mounting filesystems. After these processes complete, both indicators will be green.
The most common Status states for nodes include:
Disabled: The node is intentionally not allowed to join the cluster
Inactive: The node is not in cluster membership
Stable: The node is in membership and has mounted all of its filesystems
Any other filesystem or node status (not mentioned above) requires attention by the administrator.
Figure 4-4 shows the following:
sgiserver has Connected =green, Stable=green, and Status=Stable, indicating everything is fine.
enc-linux64 and enc-linux32 both have Connected=red, Stable=green, and Status= Disabled. This means that both systems are either powered down or not plugged in (Connected=red), but are considered stable (Stable=green) because the administrator disabled them via the CXFS management pages.
enc-mac is powered down or not plugged in (Connected=red), but is enabled; it is therefore expect it to be up, hence the Status= Inactive state and Stable=red indicator.
Because sgiserver and enc-win are the only nodes in the cluster that are actually operating correctly, they are the only nodes that have mounted the filesystem /mnt/clufs. All the other nodes are inactive or disabled, so they cannot mount that filesystem. However the filesystem itself is stable, and its status is therefore Mounted.
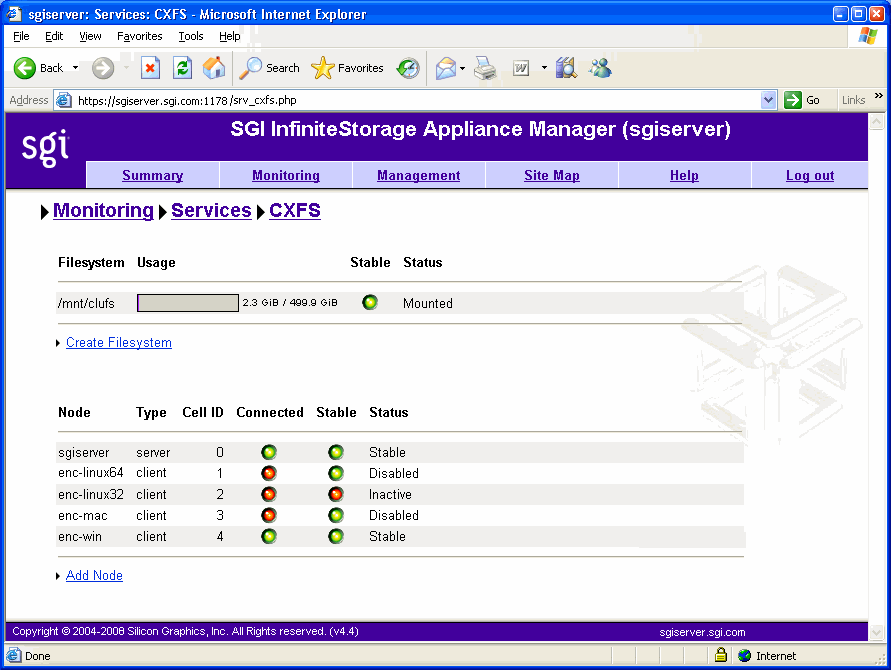
You can use the status of the nodes and filesystems as they appear on the CXFS screen to help diagnose issues. For example, when a client node is trying to mount a clustered filesystem, that client's status will be Mounted 0 of 1 filesystems. The filesystem's status will be client trying to mount. After a few seconds, the client should mount the filesystem and then both client and filesystem will be shown as Stable again.
| Note: If the client displays incorrect status or appears stuck on Mounted 0 of 1 filesystems for an extended period of time, see “CXFS Client Stuck on Filesystems Mount” in Chapter 5. |
The DMF Activity screen shows user-generated DMF activity from two points of view:
Number of requests being worked on (the Requests screen)
Rate of data throughput resulting from those requests (the Throughput screen)
| Note: Values shown on the Requests and Throughput screens are averaged over the previous few minutes, so they are not necessarily integers as would be expected. This process also causes a slight delay in the display, which means that the values of DMF Activity screens do not necessarily match the current activity on the system, as seen in the DMF log files. |
There are two distinct types of requests that are reflected in these screens:
Requests from the user to the DMF daemon. These are presented as an aggregate across the DMF server, and on a per-filesystem basis, using the label of Filesystems.
Requests from the DMF daemon to the subordinate daemons managing the back-end storage, the caches, the volume groups (VGs), and the media-specific processes (MSPs). Technically, caches are a variant of MSP despite their different purpose, hence the description Non-Cache MSP in the Appliance Manager screens.
Sometimes, there is a 1:1 correspondence between a daemon request and a back-end request by cache, volume group, or MSP (such as when a file is being recalled from back-end media back to the primary DMF-managed filesystem), but this is frequently not the case. For example, migrating a newly created file to back-end media will result in one back-end request per copy, but deleting a migrated file results in a single daemon request but no back-end request at that time. Tape merges may cause a lot of activity within a volume group but none at the daemon level.
On the top-level requests and throughput screens, and their associated History screens, for the sake of clarity the different types of requests are not distinguished from each other. However, if you zoom in (via one of the Filesystems, Caches , Volume Groups, or MSPs links on the left-hand side), the resulting screen shows the broad categories as well as by filesystem or by back-end storage group, as appropriate. This also applies to the related History screens.
The NDMP screen shows the following information about the NDMP backup operations that are currently running:
| Session ID | Displays the process ID of the NDMP session | |
| Type | Displays the type of NDMP session. There are three major types of possible session:
| |
| Start Time | Displays the time that the backup began in UNIX time (seconds since 00:00:00 UTC, January 1, 1970) | |
| DMA Host | Displays the IP address of the data mover agent (DMA) host | |
| DATA Host | Displays the IP address of the data host | |
| GiB | Displays the number of gigabytes[11]that have been transferred | |
| Throughput MiB/s | Displays the speed of throughput for the backup in megabytes[12]per second |
To stop a backup, select it and click Terminate Selected . To select all backups, click the box in the table header.
To reset the page, select Clear Selection.
A NAS client is a computer running a program that accesses the storage server. NAS clients are known to Appliance Manager by their IP address; if multiple accessing programs are running on the same computer, they are all counted as a single client.
| Note: Detailed client information is gathered only for CIFS and
NFS protocols.
The All Clients screen will not be available if neither SGI Samba nor SGI Enhanced NFS are installed. |
The All Clients screen displays the NAS clients sorted according to hostname. The other selections sort according to the chosen selection (such as by aggregate throughput).
From each of these screens, you can change the sorted display of the data without returning to the Monitoring screen.
Displaying the NAS clients in this fashion is useful for pinpointing how the current set of clients are contributing the workload profile. For example, upon noticing an unusually large amount of network traffic on the Network Throughput screen, changing to display the clients in order of aggregate throughput will quickly identify the contributing clients.
From the list of clients, you can display a detailed view of the NFS and CIFS traffic generated by a particular client. This is useful when trying to diagnose problems that affect only a single client or type of client. For example, by viewing the client detail, it may be obvious that throughput is limited by the client using very small read and write sizes. Continuing from the client details to the client history screen can help diagnose problems, such as hung NFS mounts.
The iSCSI screen displays a list of the connected iSCSI initiators are connected and their targets.