This chapter describes data placement tools you can use on an SGI Altix system. It covers the following topics:
On an SMP machine, all data is visible from all processors. Special optimization applies to SGI Altix systems to exploit multiple paths to memory, as follows:
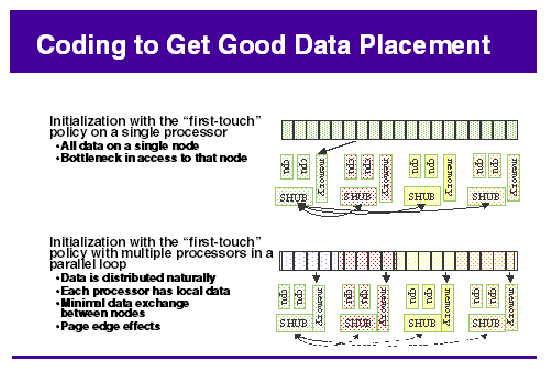
By default, all pages are allocated with a “first touch” policy.
The initialization loop, if executed serially, will get pages from single node.
In the parallel loop, multiple processors will access that one memory.
So, perform initialization in parallel, such that each processor initializes data that it is likely to access later for calculation.
Figure 5-1, shows how to code to get good data placement.
Placement facilities include cpusets, taskset(1), and dplace(1), all built upon CpuMemSets API:
cpusets -- Named subsets of system cpus/memories, used extensively in batch environments.
taskset and dplace -- Avoid poor data locality caused by process or thread drift from CPU to CPU.
taskset restricts execution to the listed set of CPUs (see the taskset -c --cpu-list option); however, processes are still free to move among listed CPUs.
dplace binds processes to specified CPUs in round-robin fashion; once pinned, they do not migrate. Use this for high performance and reproducibility of parallel codes.
For more information on CpuMemSets and cpusets, see chapter 4, “CPU Memory Sets and Scheduling” and chapter 5, “Cpuset System”, respectively, in the Linux Resource Administration Guide.
The taskset(1) command retrieves or sets a CPU affinity of a process, as follows:
taskset [options] [mask | list ] [pid | command [arg]...] |
The taskset command is used to set or retrieve the CPU affinity of a running process given its PID or to launch a new command with a given CPU affinity. CPU affinity is a scheduler property that "bonds" a process to a given set of CPUs on the system. The Linux scheduler will honor the given CPU affinity and the process will not run on any other CPUs. Note that the Linux scheduler also supports natural CPU affinity; the scheduler attempts to keep processes on the same CPU as long as practical for performance reasons. Therefore, forcing a specific CPU affinity is useful only in certain applications.
The CPU affinity is represented as a bitmask, with the lowest order bit corresponding to the first logical CPU and the highest order bit corresponding to the last logical CPU. Not all CPUs may exist on a given system but a mask may specify more CPUs than are present. A retrieved mask will reflect only the bits that correspond to CPUs physically on the system. If an invalid mask is given (that is, one that corresponds to no valid CPUs on the current system) an error is returned. The masks are typically given in hexadecimal. For example:
| 0x00000001 | is processor #0 | |
| 0x00000003 | is processors #0 and #1 | |
| 0xFFFFFFFF | is all processors (#0 through #31) |
When taskset returns, it is guaranteed that the given program has been scheduled to a legal CPU.
The taskset command does not pin a task to a specific CPU. It only restricts a task so that it does not run on any CPU that is not in the cpulist. For example, if you use taskset to launch an application that forks multiple tasks, it is possible that multiple tasks will initially be assigned to the same CPU even though there are idle CPUs that are in the cpulist. Scheduler load balancing software will eventually distribute the tasks so that CPU bound tasks run on different CPUs. However, the exact placement is not predictable and can vary from run-to-run. After the tasks are evenly distributed (assuming that happens), nothing prevents tasks from jumping to different CPUs. This can affect memory latency since pages that were node-local before the jump may be remote after the jump.
If you are running an MPI application, SGI recommends that you do not use the taskset command. The taskset command can pin the MPI shepherd process (which is a waste of a CPU) and then putting the remaining working MPI rank on one of the CPUs that already had some other rank running on it. Instead of taskset, SGI recommnds using the the dplace(1) (see “dplace Command”) or the environment variable MPI_DSM_CPULIST . The following example assumes a job running on eight CPUs. For example:
# mpirun -np 8 dplace -s1 -c10,11,16-21 myMPIapplication ... |
To set MPI_DSM_CPULIST variable, perform a command similar to the following:
setenv MPI_DSM_CPULIST 10,11,16-21 mpirun -np 8 myMPIapplication ... |
If they are using a batch scheduler that creates and destroys cpusets dynamically, you should use MPI_DSM_DISTRIBUTE environment variable instead of either MPI_DSM_CPULIST enviroment variable or the dplace command.
For more detailed information, see the taskset(1) man page.
To run an executable on CPU 1 (the cpumask for CPU 1 is 0x2), perform the following:
# taskset 0x2 executable name |
To move pid 14057 to CPU 0 (the cpumask for cpu 0 is 0x1), perform the following:
# taskset -p 0x1 14057 |
To run an MPI Abaqus/Std job on Altix 4000 series system with eight CPUs, perform the following:
# taskset -c 8-15 ./runme < /dev/null & |
The stdin is redirected to /dev/null to avoid a SIGTTIN signal for MPT applications.
The following example uses the taskset command to lock a given process to a particular CPU (CPU5) and then uses the profile(1) command to profile it. It then shows how to use taskset to move the process to another CPU (CPU3).
# taskset -p -c 5 16269 pid 16269's current affinity list: 0-15 pid 16269's new affinity list: 5 |
# profile.pl -K -KK -c 5 /bin/sleep 60
The analysis showed
====================================================================
user ticks: 0 0 %
kernel ticks: 6001 100 %
idle ticks: 5999 99.97 %
Using /boot/System.map-2.6.5-7.282-rtgfx as the kernel map file.
====================================================================
Kernel
Ticks Percent Cumulative Routine
Percent
--------------------------------------------------------------------
5999 99.97 99.97 default_idle
2 0.03 100.00 run_timer_softirq
====================================================================
Looking at the analysis for the processor, every 100th of a second,
the process has pretty much the same ip.
This might tell us that the process is in a pretty tight infinite loop.
63 16269 5 0x2000000005c3cc00 0x0005642bd60d9c5f 4 16000000
64 16269 5 0x2000000005c3cc00 0x0005642bd701c36c 4 16000000
65 16269 5 0x2000000005c3cc00 0x0005642bd7f5ea7c 4 16000000
66 16269 5 0x2000000005c3cc00 0x0005642bd8ea178a 4 16000000
67 16269 5 0x2000000005c3cc00 0x0005642bd9de3ea5 4 16000000
68 16269 5 0x2000000005c3cc00 0x0005642bdad265cb 4 16000000
69 16269 5 0x2000000005c3cbe0 0x0005642bdbc68ce6 4 16000000
70 16269 5 0x2000000005c3cc00 0x0005642bdcbab3fe 4 16000000
71 16269 5 0x2000000005c3cc00 0x0005642bddaedb13 4 16000000
72 16269 5 0x2000000005c3cc00 0x0005642bdea3021c 4 16000000
73 16269 5 0x2000000005c3cc00 0x0005642bdf97292f 4 16000000
74 16269 5 0x2000000005c3cc00 0x0005642be08b503f 4 16000000
|
# taskset -p 16269 -c 3 pid 16269's current affinity list: 5 pid 16269's new affinity list: 3 |
You can use the dplace(1) command to bind a related set of processes to specific CPUs or nodes to prevent process migration. This can improve the performance of your application since it increases the percentage of memory accesses that are local.
The dplace command allows you to control the placement of a process onto specified CPUs, as follows:
dplace [-c cpu_numbers] [-s skip_count] [-n process_name] [-x skip_mask] [-p placement_file] command [command-args] dplace -q |
Scheduling and memory placement policies for the process are set up according to dplace command line arguments.
By default, memory is allocated to a process on the node on which the process is executing. If a process moves from node to node while it running, a higher percentage of memory references are made to remote nodes. Because remote accesses typically have higher access times, process performance can be diminished. CPU instruction pipelines also have to be reloaded.
You can use the dplace command to bind a related set of processes to specific CPUs or nodes to prevent process migrations. In some cases, this improves performance since a higher percentage of memory accesses are made to local nodes.
Processes always execute within a CpuMemSet. The CpuMemSet specifies the CPUs on which a process can execute. By default, processes usually execute in a CpuMemSet that contains all the CPUs in the system (for detailed information on CpusMemSets, see the Linux Resource Administration Guide).
The dplace command invokes an SGI kernel hook (module called numatools) to create a placement container consisting of all the CPUs (or a or a subset of CPUs) of a cpuset. The dplace process is placed in this container and by default is bound to the first CPU of the cpuset associated with the container. Then dplace invokes exec to execute the command.
The command executes within this placement container and remains bound to the first CPU of the container. As the command forks child processes, they inherit the container and are bound to the next available CPU of the container.
If you do not specify a placement file, dplace binds processes sequentially in a round-robin fashion to CPUs of the placement container. For example, if the current cpuset consists of physical CPUs 2, 3, 8, and 9, the first process launched by dplace is bound to CPU 2. The first child process forked by this process is bound to CPU 3, the next process (regardless of whether it is forked by parent or child) to 8, and so on. If more processes are forked than there are CPUs in the cpuset, binding starts over with the first CPU in the cpuset.
For more information on dplace(1) and examples of how to use the command, see the dplace(1) man page.
The dplace(1) command accepts the following options:
-c cpu_numbers: The cpu_numbers variable specifies a list of CPU ranges, for example: "-c1", "-c2-4", "-c1, 4-8, 3". CPU numbers are not physical CPU numbers. They are logical CPU numbers that are relative to the CPUs that are in the set of allowed CPUs as specified by the current cpuset or taskset(1) command. CPU numbers start at 0. If this option is not specified, all CPUs of the current cpuset are available.
-s skip_count: Skips the first skip_count processes before starting to place processes onto CPUs. This option is useful if the first skip_count processes are “shepherd" processes that are used only for launching the application. If skip_count is not specified, a default value of 0 is used.
-n process_name: Only processes named process_name are placed. Other processes are ignored and are not explicitly bound to CPUs.
The process_name argument is the basename of the executable.
-x skip_mask: Provides the ability to skip placement of processes. The skip_mask argument is a bitmask. If bit N of skip_mask is set, then the N+1th process that is forked is not placed. For example, setting the mask to 6 prevents the second and third processes from being placed. The first process (the process named by the command) will be assigned to the first CPU. The second and third processes are not placed. The fourth process is assigned to the second CPU, and so on. This option is useful for certain classes of threaded applications that spawn a few helper processes that typically do not use much CPU time.

Note: OpenMP with Intel applications runnint on ProPack 2.4, should be placed using the -x option with a skip_mask of 6 (-x6). For applications compiled on ProPack 3 (or later) using the Native Posix Thread Library (NPTL), use the -x2 option.
-p placement_file: Specifies a placement file that contains additional directives that are used to control process placement. (Implemented in SGI ProPack 3 Sevice Pack 2).
command [command-args]: Specifies the command you want to place and its arguments.
-q: Lists the global count of the number of active processes that have been placed (by dplace) on each CPU in the current cpuset. Note that CPU numbers are logical CPU numbers within the cpuset, not physical CPU numbers.
Example 5-1. Using the dplace command with MPI Programs
You can use the dplace command to improve placement of MPI programs on NUMA systems and verify placement of certain data structures of a long running MPI program by running a command such as the following:
mpirun -np 64 /usr/bin/dplace -s1 -c 0-63 ./a.out |
You can then use the dlook(1) command to verify placement of certain data structures of a long running MPI program by using the dlook command in another window on one of the slave thread PIDs to verify placement. For more information on using the dlook command, see “dlook Command” and the dlook(1) man page.
Example 5-2. Using dplace command with OpenMP Programs
To run an OpenMP program on logical CPUs 4 through 7 within the current cpuset, perform the following:
%efc -o prog -openmp -O3 program.f %setenv OMP_NUM_THREADS 4 %dplace -x6 -c4-7 ./prog |
The dplace(1) command has a static load balancing feature so that you do not necessarily have to supply a CPU list. To place prog1 on logical CPUs 0 through 3 and prog2 on logical CPUs 4 through 7, perform the following:
%setenv OMP_NUM_THREADS 4 %dplace -x6 ./prog1 & %dplace -x6 ./prog2 & |
You can use the dplace -q command to display the static load information.
Example 5-3. Using the dplace command with Linux commands
The following examples assume that the command is executed from a shell running in a cpuset consisting of physical CPUs 8 through 15.
| Command | Run Location | |
| dplace -c2 date | Runs the date command on physical CPU 10. | |
| dplace make linux | Runs gcc and related processes on physical CPUs 8 through 15. | |
| dplace -c0-4,6 make linux | Runs gcc and related processes on physical CPUs 8 through 12 or 14. | |
| taskset 4,5,6,7 dplace app | The taskset command restricts execution to physical CPUs 12 through 15. The dplace command sequentially binds processes to CPUs 12 through 15. |
To use the dplace command accurately, you should know how your placed tasks are being created in terms of the fork, exec, and pthread_create calls. Determine whether each of these worker calls are an MPI rank task or are they groups of pthreads created by rank tasks? Here is an example of two MPI ranks, each creating three threads:
cat <<EOF > placefile firsttask cpu=0 exec name=mpiapp cpu=1 fork name=mpiapp cpu=4-8:4 exact thread name=mpiapp oncpu=4 cpu=5-7 exact thread name=mpiapp oncpu=8 cpu=9-11 exact EOF # mpirun is placed on cpu 0 in this example # the root mpiapp is placed on cpu 1 in this example # or, if your version of dplace supports the "cpurel=" option: # firsttask cpu=0 # fork name=mpiapp cpu=4-8:4 exact # thread name=mpiapp oncpu=4 cpurel=1-3 exact # create 2 rank tasks, each will pthread_create 3 more # ranks will be on 4 and 8 # thread children on 5,6,7 9,10,11 dplace -p placefile mpirun -np 2 ~cpw/bin/mpiapp -P 3 -l exit |
You can use the debugger to determine if it is working. It should show two MPI rank applications, each with three pthreads, as follows:
>> pthreads | grep mpiapp
px *(task_struct *)e00002343c528000 17769 17769 17763 0 mpiapp
member task: e000013817540000 17795 17769 17763 0 5 mpiapp
member task: e000013473aa8000 17796 17769 17763 0 6 mpiapp
member task: e000013817c68000 17798 17769 17763 0 mpiapp
px *(task_struct *)e0000234704f0000 17770 17770 17763 0 mpiapp
member task: e000023466ed8000 17794 17770 17763 0 9 mpiapp
member task: e00002384cce0000 17797 17770 17763 0 mpiapp
member task: e00002342c448000 17799 17770 17763 0 mpiapp |
And you can use the debugger, to see a root application, the parent of the two MPI rank applications, as follows:
>> ps | grep mpiapp 0xe00000340b300000 1139 17763 17729 1 0xc800000 - mpiapp 0xe00002343c528000 1139 17769 17763 0 0xc800040 - mpiapp 0xe0000234704f0000 1139 17770 17763 0 0xc800040 8 mpiapp |
Placed as specified:
>> oncpus e00002343c528000 e000013817540000 e000013473aa8000 >> e000013817c68000 e0 000234704f0000 e000023466ed8000 e00002384cce0000 e00002342c448000 task: 0xe00002343c528000 mpiapp cpus_allowed: 4 task: 0xe000013817540000 mpiapp cpus_allowed: 5 task: 0xe000013473aa8000 mpiapp cpus_allowed: 6 task: 0xe000013817c68000 mpiapp cpus_allowed: 7 task: 0xe0000234704f0000 mpiapp cpus_allowed: 8 task: 0xe000023466ed8000 mpiapp cpus_allowed: 9 task: 0xe00002384cce0000 mpiapp cpus_allowed: 10 task: 0xe00002342c448000 mpiapp cpus_allowed: 11 |
This section describes common reasons why compute threads do not end up on unique processors when using commands such a dplace(1) or profile.pl (see “Profiling with profile.pl” in Chapter 3).
In the example that follows, a user used the dplace -s1 -c0-15 command to bind 16 processes to run on 0-15 CPUs. However, output from the top(1) command shows only 13 CPUs running with CPUs 13, 14, and 15 still idle and CPUs 0, 1 and 2 are shared with 6 processes.
263 processes: 225 sleeping, 18 running, 3 zombie, 17 stopped
CPU states: cpu user nice system irq softirq iowait idle
total 1265.6% 0.0% 28.8% 0.0% 11.2% 0.0% 291.2%
cpu00 100.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0%
cpu01 90.1% 0.0% 0.0% 0.0% 9.7% 0.0% 0.0%
cpu02 99.9% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0%
cpu03 99.9% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0%
cpu04 100.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0%
cpu05 100.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0%
cpu06 100.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0%
cpu07 88.4% 0.0% 10.6% 0.0% 0.8% 0.0% 0.0%
cpu08 100.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0%
cpu09 99.9% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0%
cpu10 99.9% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0%
cpu11 88.1% 0.0% 11.2% 0.0% 0.6% 0.0% 0.0%
cpu12 99.7% 0.0% 0.2% 0.0% 0.0% 0.0% 0.0%
cpu13 0.0% 0.0% 2.5% 0.0% 0.0% 0.0% 97.4%
cpu14 0.8% 0.0% 1.6% 0.0% 0.0% 0.0% 97.5%
cpu15 0.0% 0.0% 2.4% 0.0% 0.0% 0.0% 97.5%
Mem: 60134432k av, 15746912k used, 44387520k free, 0k shrd,
672k buff
351024k active, 13594288k inactive
Swap: 2559968k av, 0k used, 2559968k free
2652128k cached
PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME CPU COMMAND
7653 ccao 25 0 115G 586M 114G R 99.9 0.9 0:08 3 mocassin
7656 ccao 25 0 115G 586M 114G R 99.9 0.9 0:08 6 mocassin
7654 ccao 25 0 115G 586M 114G R 99.8 0.9 0:08 4 mocassin
7655 ccao 25 0 115G 586M 114G R 99.8 0.9 0:08 5 mocassin
7658 ccao 25 0 115G 586M 114G R 99.8 0.9 0:08 8 mocassin
7659 ccao 25 0 115G 586M 114G R 99.8 0.9 0:08 9 mocassin
7660 ccao 25 0 115G 586M 114G R 99.8 0.9 0:08 10 mocassin
7662 ccao 25 0 115G 586M 114G R 99.7 0.9 0:08 12 mocassin
7657 ccao 25 0 115G 586M 114G R 88.5 0.9 0:07 7 mocassin
7661 ccao 25 0 115G 586M 114G R 88.3 0.9 0:07 11 mocassin
7649 ccao 25 0 115G 586M 114G R 55.2 0.9 0:04 2 mocassin
7651 ccao 25 0 115G 586M 114G R 54.1 0.9 0:03 1 mocassin
7650 ccao 25 0 115G 586M 114G R 50.0 0.9 0:04 0 mocassin
7647 ccao 25 0 115G 586M 114G R 49.8 0.9 0:03 0 mocassin
7652 ccao 25 0 115G 586M 114G R 44.7 0.9 0:04 2 mocassin
7648 ccao 25 0 115G 586M 114G R 35.9 0.9 0:03 1 mocassin
|
An application can start some threads executing for a very short time yet the threads still have taken a token in the CPU list. Then, when the compute threads are finally started, the list is exhausted and restarts from the beginning. Consequently, some threads end up sharing the same CPU. To bypass this, try to eliminate the "ghost" thread creation, as follows:
Check for a call to the "system" function. This is often responsible for the placement failure due to unexpected thread creation.
When all the compute processes have the same name, you can do this by issuing a command, such as the following:
dplace -c0-15 -n compute-process-name ...
You can also run dplace -e -c0-32 on 16 CPUs to understand the pattern of the thread creation. If by chance, this pattern is the same from one run to the other (unfortunately race between thread creation often occurs), you can find the right flag to dplace. For example, if you want to run on CPU 0-3, with dplace -e -C0-16 and you see that threads are always placed on CPU 0, 1, 5, and 6, then dplace -e -c0,1,x,x,x,2,3 or dplace -x24 -c0-3 (24 =11000, place the 2 first and skip 3 before placing) should place your threads correctly.
You can use dlook(1) to find out where in memory the operating system is placing your application's pages and how much system and user CPU time it is consuming.
The dlook(1) command allows you to display the memory map and CPU usage for a specified process as follows:
dlook [-a] [-c] [-h] [-l] [-o outfile] [-s secs] command [command-args] dlook [-a] [-c] [-h] [-l] [-o outfile] [-s secs] pid |
For each page in the virtual address space of the process, dlook(1) prints the following information:
The object that owns the page, such as a file, SYSV shared memory, a device driver, and so on.
The type of page, such as random access memory (RAM), FETCHOP, IOSPACE, and so on.
If the page type is RAM memory, the following information is displayed:
Memory attributes, such as, SHARED, DIRTY, and so on
The node on which the page is located
The physical address of the page (optional)
Optionally, the dlook(1) command also prints the amount of user and system CPU time that the process has executed on each physical CPU in the system.
Two forms of the dlook(1) command are provided. In one form, dlook prints information about an existing process that is identified by a process ID (PID). To use this form of the command, you must be the owner of the process or be running with root privilege. In the other form, you use dlook on a command you are launching and thus are the owner.
The dlook(1) command accepts the following options:
-a: Shows the physical addresses of each page in the address space.
-c: Shows the user and system CPU time, that is, how long the process has executed on each CPU.
-h: Explicitly lists holes in the address space.
-l: Shows libraries.
-o: Outputs to file name ( outfile). If not specified, output is written to stdout.
-s: Specifies a sample interval in seconds. Information about the process is displayed every second ( secs) of CPU usage by the process.
An example for the sleep process with a PID of 4702 is as follows:
| Note: The output has been abbreviated to shorten the example and bold headings added for easier reading. |
dlook 4702 Peek: sleep Pid: 4702 Thu Aug 22 10:45:34 2002 Cputime by cpu (in seconds): user system TOTAL 0.002 0.033 cpu1 0.002 0.033 Process memory map: 2000000000000000-2000000000030000 r-xp 0000000000000000 04:03 4479 /lib/ld-2.2.4.so [2000000000000000-200000000002c000] 11 pages on node 1 MEMORY|SHARED 2000000000030000-200000000003c000 rw-p 0000000000000000 00:00 0 [2000000000030000-200000000003c000] 3 pages on node 0 MEMORY|DIRTY ... 2000000000128000-2000000000370000 r-xp 0000000000000000 04:03 4672 /lib/libc-2.2.4.so [2000000000128000-2000000000164000] 15 pages on node 1 MEMORY|SHARED [2000000000174000-2000000000188000] 5 pages on node 2 MEMORY|SHARED [2000000000188000-2000000000190000] 2 pages on node 1 MEMORY|SHARED [200000000019c000-20000000001a8000] 3 pages on node 1 MEMORY|SHARED [20000000001c8000-20000000001d0000] 2 pages on node 1 MEMORY|SHARED [20000000001fc000-2000000000204000] 2 pages on node 1 MEMORY|SHARED [200000000020c000-2000000000230000] 9 pages on node 1 MEMORY|SHARED [200000000026c000-2000000000270000] 1 page on node 1 MEMORY|SHARED [2000000000284000-2000000000288000] 1 page on node 1 MEMORY|SHARED [20000000002b4000-20000000002b8000] 1 page on node 1 MEMORY|SHARED [20000000002c4000-20000000002c8000] 1 page on node 1 MEMORY|SHARED [20000000002d0000-20000000002d8000] 2 pages on node 1 MEMORY|SHARED [20000000002dc000-20000000002e0000] 1 page on node 1 MEMORY|SHARED [2000000000340000-2000000000344000] 1 page on node 1 MEMORY|SHARED [200000000034c000-2000000000358000] 3 pages on node 2 MEMORY|SHARED .... 20000000003c8000-20000000003d0000 rw-p 0000000000000000 00:00 0 [20000000003c8000-20000000003d0000] 2 pages on node 0 MEMORY|DIRTY |
The dlook command gives the name of the process (Peek: sleep), the process ID, and time and date it was invoked. It provides total user and system CPU time in seconds for the process.
Under the heading Process memory map, the dlook command prints information about a process from the /proc/pid/cpu and /proc/ pid/maps files. On the left, it shows the memory segment with the offsets below in decimal. In the middle of the output page, it shows the type of access, time of execution, the PID, and the object that owns the memory (in this case, /lib/ld-2.2.4.so). The characters s or p indicate whether the page is mapped as sharable (s) with other processes or is private (p). The right side of the output page shows the number of pages of memory consumed and on which nodes the pages reside. A page is 16, 384 bytes. Dirty memory means that the memory has been modified by a user.
In the second form of the dlook command, you specify a command and optional command arguments. The dlook command issues an exec call on the command and passes the command arguments. When the process terminates, dlook prints information about the process, as shown in the following example:
dlook date
Thu Aug 22 10:39:20 CDT 2002
_______________________________________________________________________________
Exit: date
Pid: 4680 Thu Aug 22 10:39:20 2002
Process memory map:
2000000000030000-200000000003c000 rw-p 0000000000000000 00:00 0
[2000000000030000-200000000003c000] 3 pages on node 3 MEMORY|DIRTY
20000000002dc000-20000000002e4000 rw-p 0000000000000000 00:00 0
[20000000002dc000-20000000002e4000] 2 pages on node 3 MEMORY|DIRTY
2000000000324000-2000000000334000 rw-p 0000000000000000 00:00 0
[2000000000324000-2000000000328000] 1 page on node 3 MEMORY|DIRTY
4000000000000000-400000000000c000 r-xp 0000000000000000 04:03 9657220 /bin/date
[4000000000000000-400000000000c000] 3 pages on node 1 MEMORY|SHARED
6000000000008000-6000000000010000 rw-p 0000000000008000 04:03 9657220 /bin/date
[600000000000c000-6000000000010000] 1 page on node 3 MEMORY|DIRTY
6000000000010000-6000000000014000 rwxp 0000000000000000 00:00 0
[6000000000010000-6000000000014000] 1 page on node 3 MEMORY|DIRTY
60000fff80000000-60000fff80004000 rw-p 0000000000000000 00:00 0
[60000fff80000000-60000fff80004000] 1 page on node 3 MEMORY|DIRTY
60000fffffff4000-60000fffffffc000 rwxp ffffffffffffc000 00:00 0
[60000fffffff4000-60000fffffffc000] 2 pages on node 3 MEMORY|DIRTY |
If you use the dlook command with the -s secs option, the information is sampled at regular internals. The output for the command dlook -s 5 sleep 50 is as follows:
Exit: sleep
Pid: 5617 Thu Aug 22 11:16:05 2002
Process memory map:
2000000000030000-200000000003c000 rw-p 0000000000000000 00:00 0
[2000000000030000-200000000003c000] 3 pages on node 3 MEMORY|DIRTY
2000000000134000-2000000000140000 rw-p 0000000000000000 00:00 0
20000000003a4000-20000000003a8000 rw-p 0000000000000000 00:00 0
[20000000003a4000-20000000003a8000] 1 page on node 3 MEMORY|DIRTY
20000000003e0000-20000000003ec000 rw-p 0000000000000000 00:00 0
[20000000003e0000-20000000003ec000] 3 pages on node 3 MEMORY|DIRTY
4000000000000000-4000000000008000 r-xp 0000000000000000 04:03 9657225 /bin/sleep
[4000000000000000-4000000000008000] 2 pages on node 3 MEMORY|SHARED
6000000000004000-6000000000008000 rw-p 0000000000004000 04:03 9657225 /bin/sleep
[6000000000004000-6000000000008000] 1 page on node 3 MEMORY|DIRTY
6000000000008000-600000000000c000 rwxp 0000000000000000 00:00 0
[6000000000008000-600000000000c000] 1 page on node 3 MEMORY|DIRTY
60000fff80000000-60000fff80004000 rw-p 0000000000000000 00:00 0
[60000fff80000000-60000fff80004000] 1 page on node 3 MEMORY|DIRTY
60000fffffff4000-60000fffffffc000 rwxp ffffffffffffc000 00:00 0
[60000fffffff4000-60000fffffffc000] 2 pages on node 3 MEMORY|DIRTY |
You can run a Message Passing Interface (MPI) job using the mpirun command and print the memory map for each thread, or redirect the ouput to a file, as follows:
| Note: The output has been abbreviated to shorten the example and bold headings added for easier reading. |
mpirun -np 8 dlook -o dlook.out ft.C.8 Contents of dlook.out: _______________________________________________________________________________ Exit: ft.C.8 Pid: 2306 Fri Aug 30 14:33:37 2002 Process memory map: 2000000000030000-200000000003c000 rw-p 0000000000000000 00:00 0 [2000000000030000-2000000000034000] 1 page on node 21 MEMORY|DIRTY [2000000000034000-200000000003c000] 2 pages on node 12 MEMORY|DIRTY|SHARED 2000000000044000-2000000000060000 rw-p 0000000000000000 00:00 0 [2000000000044000-2000000000050000] 3 pages on node 12 MEMORY|DIRTY|SHARED ... _______________________________________________________________________________ _______________________________________________________________________________ Exit: ft.C.8 Pid: 2310 Fri Aug 30 14:33:37 2002 Process memory map: 2000000000030000-200000000003c000 rw-p 0000000000000000 00:00 0 [2000000000030000-2000000000034000] 1 page on node 25 MEMORY|DIRTY [2000000000034000-200000000003c000] 2 pages on node 12 MEMORY|DIRTY|SHARED 2000000000044000-2000000000060000 rw-p 0000000000000000 00:00 0 [2000000000044000-2000000000050000] 3 pages on node 12 MEMORY|DIRTY|SHARED [2000000000050000-2000000000054000] 1 page on node 25 MEMORY|DIRTY ... _______________________________________________________________________________ _______________________________________________________________________________ Exit: ft.C.8 Pid: 2307 Fri Aug 30 14:33:37 2002 Process memory map: 2000000000030000-200000000003c000 rw-p 0000000000000000 00:00 0 [2000000000030000-2000000000034000] 1 page on node 30 MEMORY|DIRTY [2000000000034000-200000000003c000] 2 pages on node 12 MEMORY|DIRTY|SHARED 2000000000044000-2000000000060000 rw-p 0000000000000000 00:00 0 [2000000000044000-2000000000050000] 3 pages on node 12 MEMORY|DIRTY|SHARED [2000000000050000-2000000000054000] 1 page on node 30 MEMORY|DIRTY ... _______________________________________________________________________________ _______________________________________________________________________________ Exit: ft.C.8 Pid: 2308 Fri Aug 30 14:33:37 2002 Process memory map: 2000000000030000-200000000003c000 rw-p 0000000000000000 00:00 0 [2000000000030000-2000000000034000] 1 page on node 0 MEMORY|DIRTY [2000000000034000-200000000003c000] 2 pages on node 12 MEMORY|DIRTY|SHARED 2000000000044000-2000000000060000 rw-p 0000000000000000 00:00 0 [2000000000044000-2000000000050000] 3 pages on node 12 MEMORY|DIRTY|SHARED [2000000000050000-2000000000054000] 1 page on node 0 MEMORY|DIRTY ... |
For more information on the dlook command, see the dlook man page.
To use the dlook(1), dplace(1), and topology (1) commands, you must load the numatools kernel module. Perform the following steps:
To configure numatools kernel module to be started automatically during system startup, use the chkconfig(8) command as follows:
chkconfig --add numatools
To turn on numatools, enter the following command:
/etc/rc.d/init.d/numatools start
This step will be done automatically for subsequent system reboots when numatools are configured on by using the chkconfig(8) utility.
The following steps are required to disable numatools:
To turn off numatools, enter the following:
/etc/rc.d/init.d/numatools stop
To stop numatools from initiating after a system reboot, use the chkconfig (8) command as follows:
chkconfig --del numatools