This chapter describes system monitoring and covers the following topics:
This section describes some common maintenance procedures, as follows:
This section describes how to temporarily take a node offline for maintenance.
To temporarily Take a node offline for maintenance, perform the following steps:
Disable the node in the batch scheduler (depends on your batch scheduler).
Power off the node, as follows:
# cpower --down r1i0n0
Mark the node offline, as follows:
# cadmin --set-admin-status --node r1i0n0 offline
Perform any maintenance to the blade that needs to be done.
Mark the node online, as follows:
# cadmin --set-admin-status --node r1i0n0 online
Power up the node, as follows:
# cpower --boot r1i0n0
Enable the node in the batch scheduler (depends on your batch scheduler).
| Note: See your SGI field support person for the physical removal and replacement of SGI Altix ICE compute nodes (blades). |
This section describes how to permanently replace a failed blade.
To permanently replace a failed blade (compute node), perform the following steps:
Disable the node in the batch scheduler (depends on your batch scheduler).
Power off the node, as follows:
# cpower --down r1i0n0
Mark the node offline, as follows:
# cadmin --set-admin-status --node r1i0n0 offline
Physically remove and replace the failed blade.
It is not necessary to run discover-rack when a blade is replaced. This is handled by blademond daemon. See “Discovering Compute Nodes” in Chapter 2, for more information.
Set the node to boot your desired compute image (see cimage --list-images and “cimage Command” in Chapter 3 for your options), as follows:
# cimage --set mycomputeimage mykernel r1i0n0
Power up the node, as follows:
# cpower --boot r1i0n0
Enable the node in the batch scheduler (depends on your batch scheduler).
This section describes how to permanently remove a blade from your Altix ICE system.
To permanently remove a blade from your system, perform the following steps:
Disable the node in the batch scheduler (depends on your batch scheduler).
Power off the node, as follows:
# cpower --down r1i0n0
Mark the node offline, as follows:
# cadmin --set-admin-status --node r1i0n0 offline
Physically remove the failed blade.
It is not necessary to run discover-rack when a blade is replaced. This is handled by blademond daemon. See “Discovering Compute Nodes” in Chapter 2, for more information.
This section describes how to add a new blade to an Altix ICE system.
To add a new blade to your system, perform the following steps:
Physically insert the new blade
It is not necessary to run discover-rack when a blade is replaced. This is handled by blademond daemon. See “Discovering Compute Nodes” in Chapter 2, for more information.
Set the node to boot your desired compute image (see cimage --list-images and “cimage Command” in Chapter 3 for your options), as follows:
# cimage --set mycomputeimage mykernel r1i0n0
Power up the node, as follows:
# cpower --boot r1i0n0
Enable the node in the batch scheduler (depends on your batch scheduler).
This section describe how to install and configure a spare admin, leader, or managed service node. The cold spare can be a shelf spare or a factory-installed cold spare that ships with your system. For more information on cold spare requirements and tools needed to do this procedure, see “Cold Spare Admin or Leader Node Availability”.
It covers the following topics:
| Note: When ordering shelf spare systems from SGI, it is important to order spare nodes appropriate to or in conjunction with your SGI Altix ICE system. This is because the Altix ICE serial number is programmed into the admin node itself. If you try to migrate the admin node to a shelf spare system that does not have the correct Altix ICE system serial number programmed into it, parts of Tempo software may not work correctly. In particular, the Embedded Support Partner (ESP) software will fail to start if the system serial number does not match the number that was previously in use. |
Depending on the system ordered, your SGI Altix ICE system should be mounted in an SGI rack or racks. The system admin controller (admin node) and rack leader controller (leader node) are generally installed within (or in some cases on top of) the system rack. For an example, see Figure 1-1. The replacement of a failed admin node or leader node is accomplished in four basic steps:
Identify the failed unit and disconnect system and power cables.
Transfer the disk drives from the failed server into the cold spare unit.
Connect the applicable cables to the cold spare server.
Power-up the new server and restart the ICE system.
For detailed procedures on installing a cold spare, see sections“Identify the Failed Unit and Unplug all Cables”, “Transfer Disks from Existing Server to the Cold Spare”, “Migrating to a Cold Spare: Importing the Disk Volumes” and “Migrating to a Cold Spare: Booting for the First Time on the Migrated Node”.
| Note: If you are using multiple root slots (making use of cascading dual-boot as described in “Cascading Dual-Boot” in Chapter 2) the procedures described in this section will have to be repeated for each slot. |
A cold spare node is like an existing admin or leader node, but it sits on a shelf or is a factory preinstalled node to be used in an emergency.
If the admin or leader node should fail, the cold spare can be swapped in to position to take over the duities of the failed node.
If you wish to make use of cold spare nodes, SGI suggests that you have both an admin node and a leader node on the shelf as available spares. Some of the reasons to have two separate nodes instead of one are (not an exhaustive list), as follows:
The BIOS settings of an admin and leader node are different. For example, an admin node does not PXE boot by default. However, a leader node must PXE boot each boot. This means the boot order is different for each type.
The BMC of a leader node is set up to use DHCP by default. An admin node may not be set up this way.
Given the examples cited about, if you try to use a shelf-spare admin node as a leader, the leader will not be properly discovered.
Currently, the hardware replacement procedure described in this section only supports Altix ice-csn nodes, that is, admin controller and rack leader controller nodes and managed service nodes.
You will need a Video Graphics Array (VGA) screen and a keyboard to perform this procedure. This is because you need to interact with the LSI BIOS tool to import the root volumes. You cannot do this from an Intelligent Platform Management Interface (IPMI) serial console session because of the following:
For leader nodes, the cluster does not know the MAC addresses of the replacement BMC so there is no way for the cluster to connect to it until the migration script is run.
The LSI BIOS tool requires the use of Alt characters which often do not transfer through the serial console properly.
If you have already identified the failed admin node or leader node, proceed with disconnecting the cables from the failed unit. The front panel lights on the server can indicate if the unit has failed and give you information on why, see Figure 5-1.
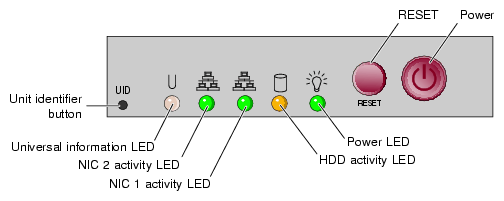
The universal information LED (left side of the panel) shows two types of failure that can bring the server down. This multi-color LED blinks red quickly to indicate a fan failure and blinks red slowly for a power failure. A continuous solid red LED indicates a CPU is overheating.
If the unit's power supply has failed or been disconnected, the power LED (far right) will be dark. Check both ends of the power cable for a firm connection prior to switching over to the cold spare.
If you find that an admin node or leader node has failed and you need to replace it with a cold spare system, this section describes what to do in terms of the physical hardware.
Admin nodes are the only node type that store the system-wide serial number. Therefore, if you use a shelf spare leader node as an admin node, ESP will fail to start properly due to the system serial number mismatch and much of the logging and monitoring infrastructure will fail to function. The admin node shelf spares must be ordered from the factory as an admin node shelf spare so that the proper serial number can be stored within.
To replace an admin node or leader node that has failed, perform the following steps:
Power down the failed node (if possible).
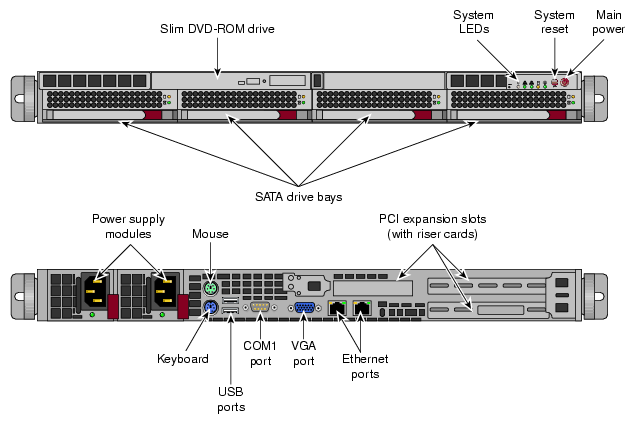
Disconnect both power cables, see Figure 5-2 for server connection locations.
Remove the two system disks from the failed node and set them aside for later reinstallation.
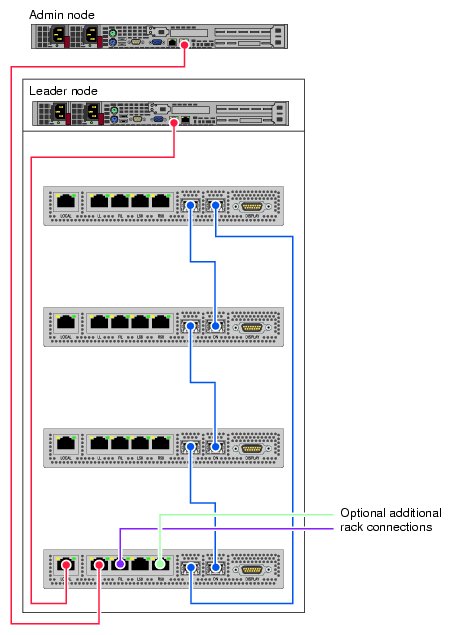
Unplug the Ethernet cable used for system management (be sure to note the plug number. Label the cables to avoid confusing them. It is important that they stay in the same jacks in the new node). See the example drawing in Figure 1-4 on page 6. This connection is vital to proper system management and communication. The Ethernet cable must be connected to the same plug on the cold spare unit.
If the unit has a system console attached, remove the keyboard, mouse, and video cables.
Remove the system from the rack.
Install the shelf spare system into the rack.
Install the system disks you set aside in step 3 (from the system you are replacing).
Connect the Ethernet cables in the same way they were connected to the replaced node.
Connect AC power.
Connect a keyboard and VGA monitor (and mouse if you like).
Do NOT power up the system just yet. Proceed to “Migrating to a Cold Spare: Importing the Disk Volumes”.
| Note: The factory-installed cold spare does NOT ship with disks so you need to transfer existing disks and PCI cards from the existing server to the cold spare before mounting the spare rack. |
Transfer disks from the existing server to the cold spare as shown in Figure 5-3.
This section describes how to import the disk volumes into the new node installed in “Identify the Failed Unit and Unplug all Cables”.
| Note: This section does not apply to SGI Altix XE250 systems with MegaRAID SAS/SATA storage hardware. |
To import the disk volumes into the new node, perform the following steps:
At this time, you can power up the system using the power button.
Watch the VGA screen output.
When you see the LSI BIOS tool come up up, enter Ctrl-C. This will instruct the LSI BIOS tool to enter the configuration utility.
A screen appears listing the LSI controllers in the system. Normally, there is just one. Hit the Enter key to proceed.
Choose RAID Properties.
It is important to note that the controller supports only two RAIDs at a time. Therefore, if the system had two volumes at a time in the past, one or more volumes may appear empty now. It is important to use the utility to delete these empty volumes representing disks that are no longer installed before proceeding. Otherwise, if the tool sees more than one volume, activating volumes will not work.
Enter Alt-N to browse the list of volumes. Delete the empty ones as described in the step, above. Eventually, you will encounter an inactive volume. This inactive volume represents the disks you migrated from the failed node to this node.
With the inactive volume selected, choose Manage Array.
Choose Activate and answer y to the activate and exit this menu choice.
At this point, especially if the node has more than one volume, it is important to select the migrated system disk volume as the boot volume. To select the boot volume, choose SAS Topology .
In SAS Topology, you can expand the volumes to see the disks within them if you choose by hitting Enter on volumes.
Choose the volume that represents your newly imported volume. Highlight it, then enter Alt-B.
You should see that the volume now has a Boot flag associated with it.

Note: If, after you exit the tool, the system does not appear to boot from the disk. You may have selected the wrong volume from which to boot. In that case, reset, re-enter the LSI BIOS Tool, and choose a different volume to be the boot volume.
Escape out of the LSI tool and exit.
Keep watching the VGA screen! You will have to hit a key at the correct moment in the next section. Go to “Migrating to a Cold Spare: Booting for the First Time on the Migrated Node”.
This section provides information on booting the system for the first time on a replacement node.
| Note: Important: If your site is using cascading dual boot, only the currently used slot will be updated or repaired. Therefore, if the admin node is booted to slot 2, the fix up operations documented in these sections only apply to slot 2. The instructions need to be done for each slot you wish to fix up. |
In a prior release, utomatic recovery was implemented for cascading dual boot clusters. This means, if cascading dual boot is in use, when a managed service node or leader boots after having procedure 5-6 performed, it will go in to an automatic recovery boot, perform some fix up, then reboot again in to its normal operating mode. For the case of the admin node, a script is run by hand to integrate the repaired admin node with the cluster.
For the case of the admin node, you will need to ensure your console output goes to the VGA screen and not serial-over-lan (SOL). For managed service nodes and leaders in cascading dual boot clusters, the default output location during the auto recovery boot is VGA. It is best to leave it VGA since part of the repair procedure will affect the network configuration for the BMC.
How do I know which procedure to follow?
Admin nodes, all cases: Procedure 5-7. Migrating to a Cold Spare: Booting the Admin or leader/service node in non-cascading dual boot clusters for the first time.
Managed Service, Leader nodes in a NON-cascading dual boot cluster: Procedure 5-7. Migrating to a Cold Spare: Booting the Admin or leader/service node in non-cascading dual boot clusters for the first time
Managed service, Leader nodes in a cascading dual boot cluster: Procedure 5-8. Migrating to a Cold Spare: service/leader nodes using Cascading Dual Boot.
This section describes how to boot the admin node or a leader or service node in non-cascading dual boot clusters.
| Note: This section applies to admin nodes and sites that are not making use of cascading dual boot. Cascading dual boot is set up by default on newer SMC for Altix ICE software releases. If you are using cascading dual boot, follow these instructions only for the admin node. |
To boot for the first time on a migrated node, perform the following steps:
Ensure that the VGA console is powered on.
At this moment, the node is in the process of resetting because you exited the LSI BIOS tool at the end of the procedure, above (see “Migrating to a Cold Spare: Importing the Disk Volumes”).
Note: After rebooting, drive 1 will resync with drive 0, automatically. Drive 1 will have the RED LED on during this time. This process takes from eight to 48 hours depending on the drive size. During that period, the RAID redundancy is not available but the system will function normally.
When you see the GRUB boot menu come up, the first boot option will be highlighted by default. This should NOT be the choice starting with Failsafe. As an example, in SMC for Altix ICE 1.0 the highlighted choice should be : SUSE Linux Enterprise Server 10 SP3. Enter e to edit the boot parameters for this boot only.Enter e to edit the kernel parameters.
Arrow down once so that the line starting kernel is highlighted.
Look at the settings. If no serial console is defined, you do not need to change anything. If a serial console is defined, append "console=tty0" to the end of the parameter list. This will ensure that console output goes to the VGA screen for this boot.
Note: By default, the admin node output goes to the VGA screen. Therefore, this adjustment does not need to be made. Leader and service nodes have serial consoles by default.
Press the Enter key.
Enter b to boot the system.
The system will now boot with console output going to the VGA screen.
Networking will fail to start and some error messages will appear.
It is normal to see that the Ethernet devices were renumbered. This will be fixed below.
Eventually the login prompt will appear.
Log in as root.
The following script fixes the network settings and update the SMC for Altix ICE database for the new network interfaces, as follows:
# migrate-to-shelf-spare-node
Note: If you have additional Ethernet cards installed, you may need to check the settings of interfaces not controlled or managed by SMC for Altix ICE software.
Reboot the node and let it boot normally.
This section describes what to do for managed service nodes and leader nodes in a cluster making use of cascading dual boot. It does not apply to admin nodes. For admin nodes, see Procedure 5-7.
To boot for the first time on a migrated node, perform the following steps:
Ensure that the VGA console is powered on.
At this moment, the node is in the process of resetting because you exited the LSI BIOS tool at the end of the procedure, above (see “Migrating to a Cold Spare: Importing the Disk Volumes”).
Note: After rebooting, drive 1 will resync with drive 0, automatically. Drive 1 will have the RED LED on during this time. This process takes from eight to 48 hours depending on the drive size. During that period, the RAID redundancy is not available but the system will function normally.
At this time, you can plug the node in to AC power and press the power button on the front of the node.
Watch the VGA screen. The system should network boot in to recovery mode. It will do some repairs and reboot itself.
At this point, it will boot as a normal node. If, for some reason, it is unable to boot from the disk, the wrong volume may be selected as the boot disk in the LSI BIOS tool (see “Migrating to a Cold Spare: Importing the Disk Volumes”). It is true that the node network boots, but the network boot does a chainload to the first disk and it is still impacted by the BIOS and LSI firmware settings.
This section gives some advanced details on the Auto Recovery feature including how it is set up and how to control the feature.
The auto recovery feature allows managed service nodes and leader nodes to automatically make the necessary adjustments for both the node setup itself and the SMC for Altix ICE cluster database. This feature is mainly useful for clusters making use of cascading dual boot. The automated recovery mode applies to managed service nodes and leader nodes in cascading dual boot clusters. The goal is to provide an easy way for these nodes to perform any fix ups to themselves and the SMC for Altix ICE cluster at large when faulty systems are replaced.
Your site may prefer to disable the auto recovery mode. This can be done by using the cadmin command. These commands apply:
--enable-auto-recovery --disable-auto-recovery --show-auto-recovery |
Four IP addresses are reserved on the head network for auto recovery operations. For clusters being installed for the first time, these tend to be low numbers as they are reserved before any service or leader nodes are discovered. For systems being upgraded from previous SMC for Altix ICE releases, the allocated IP addresses are allocated the first boot after the upgrade and would tend to have higher numbers.
When the auto recovery feature is enabled, the dhcpd.conf file is configured with DHCP addresses available to unknown systems. That is, when this mode is enabled, any system attached to the head network that is performing DHCP requests will get a generic pool address and then boot in to the auto recovery mode. When the auto recovery mode is disabled, DHCP is configured to not offer these special IP addresses.
The auto recovery mode conflicts with the way that the discover command operates by default. Therefore, the discover command automatically and temporarily disables auto recovery (if it was enabled) for the duration of the run of the discover command. For more information on the discover command, see “discover Command” in Chapter 2.
If you plan to discover a node, start discover before applying AC power. This is because auto recovery provides IP addresses to unknown nodes and because the discover command temporarily disables this, it is best to start the discover command before plugging in AC power to the node being discovered. Otherwise, it may get an unintended IP address.
SGI Altix ICE is a diskless blade server typically configured with nfs root and a small (50 MB) swap space that is served via iscsi. A maximum of 64 blades boot from a rack leader controller (leader node). The leader node typically has SATA disks in a mirrored pair for blade filesystems and blade swap space. Some users turn off swap entirely because a full rack of blades swapping has proven to be stressful to the rack leader nodes. When a Linux system has more memory requests than it can provide the kernel takes steps to defend the system using the out of memory (OOM) killer. The following section describes strategies for avoiding the loss of ICE blades due to OOM occurrences when the operating system is SLES11 and the batch scheduler is PBS Pro.
Some general guidelines are, as follows:
Requesting the proper amount of memory is the first and most important strategy.
If your application is correctly asking for memory then with PBS Pro configure MOM to enforce memory limits. “The Job Executor or MOM is the daemon/service which actually places the job into execution. This process, pbs_mom, is informally called MOM as it is the mother of all executing jobs.” See the PBS Professional 9.2 User's Guide for a complete description of MOM.
This only works well with when the SGI memacct function is installed to properly compute the amount of memory used. This requires that Linux kernel jobs and Comprehensive System Accounting (CSA) are installed. For more information, see the Linux Resource Administration Guide. CSA does not have to be configured to log. Modify /var/spool/PBS/mom_priv/config file by adding $enforce mem to the file. As an example, an application that just allocates memory one megabyte at a time will be killed once it goes over the limit. Applications that allocate in bigger chunks can still get above the limit before PBS can kill the job.
The PBS Pro enforce mem variable has no configuration options. To avoid OOM occurrences you need your own daemon, such as the policykill daemon.
The policykill daemon looks for swapping in cpusets and works well in both large single-system image (SSI) with multiple cpusets and cluster (single cpuset). On large SSI, use of PBSPro's cpuset mom is required. On Altix ICE systems use of SGI Altix bundle (example PBSPro_10.1.0-SGIAltix_pp6_x86_64.tar.gz) from Altair Engineering, Inc. is suggested. policykill has an init script, configuration file and daemon process itself. It requires customization for limits and notification methods.
The Linux kernel Out Of Memory killer (mm/oom_kill.c ) is responsible for keeping the system alive when memory has been exhausted. A snippet from the code is, as follows:
* The formula used is relatively simple and documented inline in the * function. The main rationale is that we want to select a good task * to kill when we run out of memory. * * Good in this context means that: * 1) we lose the minimum amount of work done * 2) we recover a large amount of memory * 3) we don't kill anything innocent of eating tons of memory * 4) we want to kill the minimum amount of processes (one) * 5) we try to kill the process the user expects us to kill, this * algorithm has been meticulously tuned to meet the principle * of least surprise ... (be careful when you change it)
You can use arrayd to manage what processes gets killed. For more information on arrayd, see the arrayd(8) man page and Chapter 3. “Array Services” of the Linux Resource Administration Guide. arrayd has a configuration option to protect the daemon:
-oom oom_daemon,oom_child Specify oom_adj ( OutOfMemory Adjustments ) respectively for the main arrayd daemon and each arrayd children. The default is "-17,0", hence resulting in the arrayd daemon never being selected as a candidate by the oom kernel killer thread and children selected as normal candi dates. The value range from -17 to 15.
Each pid has an oom_adj ( /proc//oom_adj) that you can independently protect. In general, you want root owned processes to be protected and user processes to be able to be killed.
A combination of PBS prologue and cron can set the values at job start and through the job's life span. On Altix ICE systems with SMC for Altix ICE, cron is configured off in 80-compute-distro-services which is in
/var/lib/systemimager/images/<your compute image>/etc/opt/sgi/conf.d/80-compute-distro-services
by commenting out the following line:initDisableServiceIfExists cron
To just enable cron on a blade is not a good practice. Files in
/var/lib/systemimager/images/<your compute image>/etc/cron*
must be reviewed for correctness in mixed writeable and read-only environment. For example, sysstat, logrotate, suse.de-cron-local, are the only services available in /etc/cron* directories. For a list of sample scripts, see Appendix A, “Out of Memory Adjustment”.Virtual memory sysctl tuning tries to balance use of system resources for user jobs and for system threads. The default setup is skewed towards user jobs but in the face of OOM system threads need more resources. For more information on sysctl, see the sysctl(8) man page. For an SGI Altix ICE system running with SMC for Altix ICE software, the sysctl parameters might be predefined similar to the following:
# Give the kernel a bit more breathing room by requiring more free space vm.min_free_kbytes = 131072 # Push dirty pages out faster vm.dirty_expire_centisecs = 1000 # Default is 3000 vm.dirty_writeback_centisecs = 500 # Default (unchanged) vm.dirty_ratio = 20 # Default is 40 vm.dirty_background_ratio = 5 # Default is 10
If blades are run without swap, set the following variable:
vm.swappiness = 0
You can use the SMC for Altix ICE inventory verification tool to query, take snapshots, analyze and compare the node and network inventory of a cluster. Various hardware, network and operating system configuration properties are available and are presented in user-specified formats.
| Note: If you are reinstalling the system admin controller (admin node), you may want to make a backup of the cluster configuration snapshot that comes with your system so that you can recover it later. You can find it in the /opt/sgi/var/ivt directory on the admin node; it is the earliest snapshot taken. You can use this information with the interconnect verification tool (IVT) to verify that the current system shows the same hardware configuration as when it was shipped. For more information, see “Installing SMC for Altix ICE Admin Node Software ” in Chapter 2. |
To make an inventory snapshot of an Altix ICE system, use the following command from the system admin controller (admin node).
admin:~ # ivt -M Making a cluster inventory snapshot. Takes a couple of minutes... |
Each snapshot is assigned a unique number and marked with the date and time it was taken. Use the ivt -L command to list active snapshot information, as follows:
admin:~ # ivt -L
1 2007-07-13.11:42:47 |
You can query (-Q option), compare ( -C option) and analyze (-S option) existing snapshots. A variety of system hardware and configuration properties can be displayed. You can compare two snapshots to see what has changed or analyze a system snapshot for failed nodes and or see network fabric links.
You can use the ivt -c cpu command to show an inventory of the system compute blades and the number of CPUs each blade contains, as follows:
admin:~ # ivt -c cpu r1i0n0 has 8 CPUs r1i0n1 has 8 CPUs r1i0n8 has 8 CPUs r1i1n0 has 8 CPUs r1i1n1 has 8 CPUs r1i1n8 has 8 CPUs |
You can use the ivt tool to determine which compute nodes (blades) are up or down, as follows:
admin:~ # ivt -Q -w blades -f '$blade $sshstate' r1i0n0 up r1i0n1 down r1i0n8 up r1i1n0 up r1i1n1 down r1i1n8 up |
You can use the ivt tool to determine the GigE Ethernet address for each compute node (blade) , as follows:
admin:~ # ivt -Q -w blades -f '$blade $gige_ip_addr' r1i0n0 192.168.159.10 r1i0n1 192.168.159.11 r1i0n8 192.168.159.18 r1i1n0 192.168.159.26 r1i1n1 192.168.159.27 r1i1n8 192.168.159.34 |
For detailed information on how to use the ivt tool, see the ivt(8) man page or ivt -h, --help usage statement.
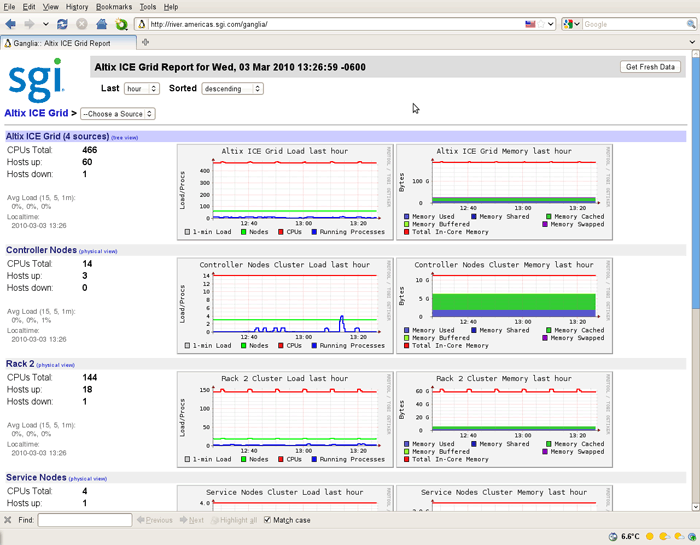
Ganglia is a scalable, distributed monitoring system for monitoring system for high-performance computing systems, such as the SGI Altix ICE system. It displays web browser-based, real-time (on demand) histograms of system metrics, as shown in Figure 5-4.
Detailed information about the Ganglia monitoring system is available at: http://ganglia.info/.
SMC for Altix ICE has devised a Ganglia model for the Altix ICE system that makes maximum use of Ganglia's highly scalable architecture: each compute node (blade) presents a single monitoring source sending its statistics to the rack leader controller. Therefore, the rack leader controller receives, at most, data from 64 blades. After collecting the data, the rack leader controller forwards aggregated rack statistics to the system admin controller (admin node). The rack leader controller also sends its own statistics to the system admin controller. The system admin controller presents the meta-aggregator for the entire Altix ICE system. It collects data from all rack leaders and presents the cluster-wide metrics. This model enables SGI to scale-out Ganglia to very large cluster deployments.
The Node View as shown in Figure 5-5 can aid in system troubleshooting. For every blade in the system, the Location field of the Node View shows the exact physical location of the blade. This is an extremely useful when trying to locate a blade that is down.
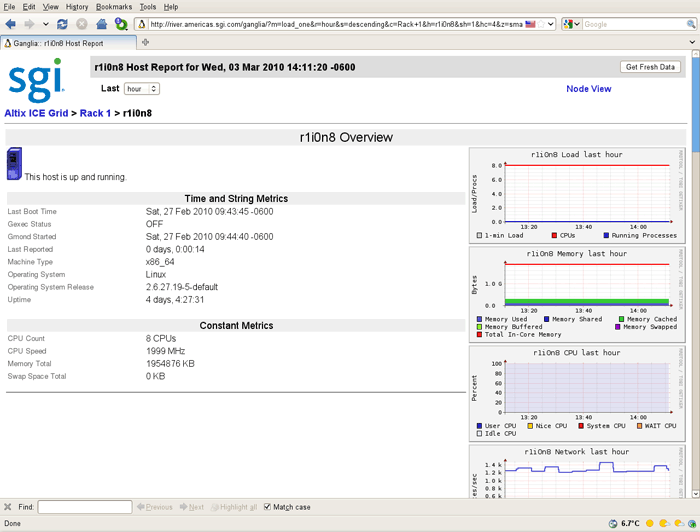
This section describes the operation of the Ganglia system monitor and covers the following topics:
To access the Ganglia system monitor, point your browser to the following location: http://admin_pub_name /ganglia
By default, Ganglia monitors standard operating system metrics like CPU load, memory usage. The Grid Report view shows an overview of your system, such as the number of CPUs, the number of hosts (compute nodes) that are up or down, service node information, memory usage information, and so on.
The Last pull down menu allows you to view performance data on an hourly, daily, weekly, or yearly basis. The Sorted pull down menu allows provides an ascending, descending, or by host view of performance data. The Grid pull-down menu allows you to see performance data for a particular rack or service node. The Get Fresh Data button allows you to see current data performance.
The system admin controller, rack leader controllers, the service nodes, the chassis management controllers (CMCs) and all the compute nodes (blades) are equipped with a specialized controller, called the Board Management Controller (BMC). This unit provides a broad set of functions as described in the IPMI 2.0 standard. SMC for Altix ICE software uses the BMCs predominantly for remote power management, remote system configuration, and for gathering critical hardware events.
Currently, critical hardware events are gathered for the following nodes: rack leader controllers (leader nodes), CMCs and compute nodes (blades). These events are logged in the following locations:
/var/log/messages via syslog
var/log/sel/sel.log
Embedded Support Partner (ESP)
Whenever critical hardware event occurs, information is forwarded about the event to all three locations. You can observe a critical hardware event via syslog, via sel.log or using ESP. Furthermore, administrator-defined actions can be triggered via ESP, for instance sending an e-mail notification to the system administrator. For more information on ESP, see esp(5) man page and the SGI Embedded Support Partner User Guide.
All critical hardware events are summarized under the BMC_CMC event type. One particular event holds the following useful information:
MSG ::= <syslog-prefix> SMC:<node> EVENT:<event> APP:<app> Date:<date> VERSION:<version> TEXT <text> |
The following fields are all of the type string:
| <node> | node name, for example, r1i0n5 | |
| <event> | BMC_CMC | |
| <app> | SEL-LOGGER | |
| <date> | date / time of the event | |
| <version> | 1.0 | |
| <text> | Exact copy of the hardware event description from the BMC |
After reading the events from the BMCs, the BMC event logs are cleared on the controller to avoid duplicate events.
The availability of each node in an SGI Altix ICE system is monitored by a lightweight daemon called smchbc. Each managed service node, rack leader controller (leader node), and compute node runs this daemon and reports its status to the server which monitors it. The server daemon, which runs on the admin node and leader nodes, reports if the client is down after approximately 120 seconds. In this event, a HEARTBEAT Embedded Support Partner (ESP) event is generated. You can observe this event via syslog or using ESP. Furthermore, administrator-devined actions can be triggered, for instance sending an e-mail notification to the system administrator. For more information on ESP, see esp(5) man page and the SGI Embedded Support Partner User Guide.
The HEARTBEAT event contains the following useful information:
MSG ::= <syslog-prefix> SMC:<node> EVENT:HEARTBEAT APP:SMCHBD Date:<date> VERSION:1.0 TEXT <text> |
The HEARTBEAT event is created when nodes fail or recover, described by the TEXT field.
The following fields are all of the type string:
| <node> | node name, for example, r1i0n5 | ||
| <date> | date / time of the event | ||
| <text> | Description of event:
|
A wealth of system metrics are also available through the Performance Co-Pilot (see Performance Co-Pilot Linux User's and Administrator's Guide). The Performance Co-Pilot collection daemon (PMCD) runs on the admin node, managed service nodes, and rack leader nodes. A performance metrics domain agent (PMDA) is running on the rack leader nodes, which collects metrics from the compute nodes.
The new cluster metrics domain contains metrics that were previously available in other PMDAs. The method in which they are collected is different in a SMC for Altix ICE system, in order to minimize load on the compute nodes. The following metrics are available for each compute node in a system by querying the PMCD on their rack leader node:
admin:~ # pminfo -h r1lead cluster cluster.control.suspend_monitoring cluster.kernel.percpu.cpu.user cluster.kernel.percpu.cpu.sys cluster.kernel.percpu.cpu.idle cluster.kernel.percpu.cpu.intr cluster.kernel.percpu.cpu.wait.total cluster.mem.util.free cluster.mem.util.bufmem cluster.mem.util.dirty cluster.mem.util.writeback cluster.mem.util.mapped cluster.mem.util.slab cluster.mem.util.cache_clean cluster.mem.util.anonpages cluster.network.interface.in.bytes cluster.network.interface.in.errors cluster.network.interface.in.drops cluster.network.interface.out.bytes cluster.network.interface.out.errors cluster.network.interface.out.drops cluster.network.ib.in.bytes cluster.network.ib.in.errors.drop cluster.network.ib.in.errors.filter cluster.network.ib.in.errors.local cluster.network.ib.in.errors.remote cluster.network.ib.out.bytes cluster.network.ib.out.errors.drop cluster.network.ib.out.errors.filter cluster.network.ib.total.errors.link cluster.network.ib.total.errors.recover cluster.network.ib.total.errors.integrity cluster.network.ib.total.errors.vl15 cluster.network.ib.total.errors.overrun cluster.network.ib.total.errors.symbol |
The list of metrics that are monitored by the compute node and are pushed to the PMCD on the leader node is configurable. In some cases , it may be even be desirable to disable metric collection entirely, as follows:
# cexec --head --all pmstore cluster.control.suspend_monitoring 1 pmstore -h r1lead cluster.control.suspend_monitoring 1 |
The default list of metrics that are collected by each compute node contains 41 metrics. There are dozens more available in the cluster.* namespace. The default list is stored on each leader node in the /var/lib/pcp/pmdas/cluster/config file. Changing this file will allow you to modify the default metric list with rack granularity. To change the list on a single node store a newline-delimited list of metrics to the node's instance of the cluster.control.metrics metric.
To see the current metric list for a compute node, perform the following:
# pmval -h r1lead -s 1 -i 'r1i1n0' cluster.control.metrics
metric: cluster.control.metrics
host: r1lead
semantics: discrete instantaneous value
units: none
samples: 1
r1i1n0
"cluster.kernel.percpu.cpu.user
cluster.kernel.percpu.cpu.nice
cluster.kernel.percpu.cpu.sys
cluster.kernel.percpu.cpu.idle
cluster.kernel.percpu.cpu.intr
cluster.kernel.percpu.cpu.wait.total
cluster.mem.util.free
cluster.mem.util.bufmem
cluster.mem.util.dirty
cluster.mem.util.writeback
cluster.mem.util.mapped
cluster.mem.util.slab
cluster.mem.util.cache_clean
cluster.mem.util.anonpages
cluster.infiniband.port.rate
cluster.infiniband.port.in.bytes
cluster.infiniband.port.in.packets
cluster.infiniband.port.in.errors.drop
cluster.infiniband.port.in.errors.filter
cluster.infiniband.port.in.errors.local
cluster.infiniband.port.in.errors.remote
cluster.infiniband.port.out.bytes
cluster.infiniband.port.out.packets
cluster.infiniband.port.out.errors.drop
cluster.infiniband.port.out.errors.filter
cluster.infiniband.port.total.bytes
cluster.infiniband.port.total.packets
cluster.infiniband.port.total.errors.drop
cluster.infiniband.port.total.errors.filter
cluster.infiniband.port.total.errors.link
cluster.infiniband.port.total.errors.recover
cluster.infiniband.port.total.errors.integrity
cluster.infiniband.port.total.errors.vl15
cluster.infiniband.port.total.errors.overrun
cluster.infiniband.port.total.errors.symbol
cluster.network.interface.in.bytes
cluster.network.interface.in.errors
cluster.network.interface.in.drops
cluster.network.interface.out.bytes
cluster.network.interface.out.errors
cluster.network.interface.out.drops
" |
An example that changes the metric list to only include the CPU metrics for r1i1n0 is, as follows:
# pmstore -h r1lead -i 'r1i1n0' cluster.control.metrics 'cluster.kernel.percpu.cpu.user cluster.kernel.percpu.cpu.nice cluster.kernel.percpu.cpu.sys cluster.kernel.percpu.cpu.idle cluster.kernel.percpu.cpu.intr cluster.kernel.percpu.cpu.wait.total |
The sensor data repository (SDR) metrics are available through Performance Co-Pilot (see Performance Co-Pilot Linux User's and Administrator's Guide). The SDR provides temperature, voltage, and fan speed information for all service nodes, leader nodes, compute nodes, and CMCs. This information is collected from service and compute nodes through their BMC interface, so it is out-of-band and does not impact the performance of the node.
The following metrics are available through the PMCD:
admin:~ # pminfo -h r1lead sensor sensor.value.fan sensor.value.voltage sensor.value.temperature |
Each sensor will have a separate instance within the domain, with the instance of the form:
<nodeName>:<nodeType>:<metricName> nodeName ::= SMC for Altix ICE node names (rXlead, rXiYc, rXiYnZ) nodeType ::= "service", "cmc", "blade", "leader" |
For example, to view voltages for the rack leader node, perform the following
admin:~ # pminfo -h r1lead -f sensor.value.voltage | grep -E '(^$|^sensor|r1lead)'
sensor.value.voltage
inst [0 or "r1lead:leader:CPU1_Vcore"] value 1.3
inst [1 or "r1lead:leader:CPU2_Vcore"] value 1.3
inst [2 or "r1lead:leader:3.3V"] value 3.26
inst [3 or "r1lead:leader:5V"] value 4.9
inst [4 or "r1lead:leader:12V"] value 11.71
inst [5 or "r1lead:leader:-12V"] value -12.3
inst [6 or "r1lead:leader:1.5V"] value 1.47
inst [7 or "r1lead:leader:5VSB"] value 4.9
inst [8 or "r1lead:leader:VBAT"] value 3.31 |
For additional examples on how to retrieve values using pmval(1) and for using this data in trend analysis using pmie(1), see the appropriate man page and the Performance Co-Pilot Linux User's and Administrator's Guide.
Currently, in temperature.pmie there are values that will "Monitor: shut down components if temp too high" . This feature is enabled by default as a safety mechanism. The procedure below describes how to turn it off.
To turn off the temperature.pmie feature, perform the following steps:
Edit the /var/lib/pcp/config/pmie/control file to comment out or remove the line that calls /opt/sgi/lib/temperature.pmie. For example,
#LOCALHOSTNAME n PCP_LOG_DIR/pmie/LOCALHOSTNAME/temperaturepmie.log -c /opt/sgi/lib/temperature.pmie
Run the /etc/init.d/pmie restart command. If you just want to adjust temperature.pmie values, see “Adjusting temperature.pmie Values”.
This has to be done on the admin and leader nodes. In that case, it is recommended that you turn it off on the leader images too.
This section describes how to adjust temperature.pmie values.
You can adjust the warning or shutdown temperature values manually on the admin node and on each one of the leader nodes (if you choose to). In that case, it is recommended that you adjust it on the leader images too. The settings will be preserved between reboots. To change the values, perform the following steps:
Edit the /opt/sgi/lib/temperature.pmie file:
admin_warning_temperature = 68; // degree Celsius admin_shutdown_temperature = 73; // degree Celsius leader_warning_temperature = 68; // degree Celsius leader_shutdown_temperature = 73; // degree Celsius service_warning_temperature = 68; // degree Celsius service_shutdown_temperature = 73; // degree Celsius cmc_warning_temperature = 48; // degree Celsius cmc_shutdown_temperature = 53; // degree Celsius cn_warning_temperature = 68; // degree Celsius cn_shutdown_temperature = 73; // degree Celsius sensor_temperature = "sensor.value.temperature"; // degree Celsius
Perform the following command to verify that you updated the script correctly, as follows:
# pmie -C /opt/sgi/lib/temperature.pmie
If there are no errors, the pmie -C command returns with no message.
Run the /etc/init.d/pmie restart command or the service pmie restart command to restart the pmie service.
To turn off the temperature.pmie value, see “Turning Off the temperature.pmie Feature”.
You can use the Cluster Performance Monitor to monitor your Altix ICE system. Log into the admin node using the ssh -X command. Execute the pmice command and the pmice - Cluster Performance Monitor appears, as follows:

For a usage statement, use the pmice --h command, as follows:
admin:~ # pmice --h /usr/bin/pmice: illegal option -- - Info: Usage: pmice [options] [pmgadgets options] options: -K list Show these CPUs. Comma-separated list -N list Show these nodes. Comma-separated list -R list Show these racks. Comma-separated list -V Verbose/diagnostic output pmgadgets(1) options: -C check configuration file and exit -h host metrics source is PMCD on host -n pmnsfile use an alternative PMNS -t interval sample interval [default 2.0 seconds] -z set reporting timezone to local time of metrics source -Z timezone set reporting timezone -zoom factor make the gadgets bigger by a factor of 1, 2, 3 or 4 -infofont fontname use fontname for text in info dialogs -defaultfont fontname use fontname for label gadgets -display display-string -geometry geometry-string -name name-string -title title-string -xrm resource |
The Embedded Support Partner (ESP) is a software suite to monitor events, set up proactive notification, and generate reports on SGI Altix systems. This section describes how to set it up on an SGI Altix ICE system. For detailed information about ESP, see Embedded Support Partner User Guide.
To set up ESP on an SGI Altix ICE system, perform the following steps:
From the admin node, use the chkconfig command to make sure that the state of ESP is on, as follows:
admin:~ # chkconfig --list | grep esp esp 0:on 1:on 2:on 3:on 4:on 5:on 6:on sgi-esphttp: on sgi_espd: on
ESP should already be running if its chkconfig flag is on. You can interact with ESP using a web interface or the command line (see Chapter 4, “Setting Up the ESP Environment” in the Embedded Support Partner User Guide.
From the admin node, create the default ESP user account, as follows:
admin:~ # espconfig -createadmin
Enable the hosts that will be allowed to access ESP with the following commands:
admin:~ # espconfig -enable ipaddr 127.0.0.0 admin:~ # espconfig -enable ipaddr 127.0.0.1 admin:~ # espconfig -enable ipaddr IP_address_of_client
From your laptop or PC system, point your browser to http://mymachine__-admin:5554 and log into ESP.
When the ESP login screen appears, login as administrator, use the password partner. After you login, the System Information screen appears (see Chapter 2, “Accessing ESP” Embedded Support Partner User Guide.
Now enter the Customer Profile information, as follows:
Select ESP Administration from the menu.
Click on Customer Profile (if not selected by default).
Fill in the form and then click Add.
Click Commit; or Update if already filled out.
Use ESP to Examine Inventory, as follows:
Select Reports Hardware Generate Report.
Select Reports Software Generate Report.
You can search for individual packages by entering the name in the search box (below the system host name) and then selecting GO on the right hand side of the screen. You can also use the down arrow to select a package in this search box.
Use ESP to enable or disable Performance Monitoring, as follows:
Select Configuration (from the top level menu) and then select Performance Monitoring.
Enable PMIE.
Disable the PMIE rule cpu.util.
Select Commit.
Select Configuration System Monitoring and enable the service pmcd.
Select Update and Commit (this may take a few minutes).
Use ESP to examine errors logs, as follows:
From the top level menus, select Report Events .
Then select Last 30 days and All Classes before clicking on Generate Report.
Use ESP to enable or disable Notification
Notification of events is handled by espnotify. The notication can be of types e-mail, system console, or graphics console. The notifications are enabled or disabled by specific actions. So after configuring the notification action you can enable or disable the notification, as follows:
Select Configuration Actions and click Continue.
Decide on the notification format and then check and select Continue and Commit .
Select Enable/ Disable from the third level menu, and click to enable the notification you set up.
Click Commit.
This section describes some troubleshooting tools and covers these topics:
You can run the dbdump script to see an inventory of the Altix ICE database.
The dbdump command is, as follows:
/opt/sgi/sbin/dbdump --admin /opt/sgi/sbin/dbdump --leader /opt/sgi/sbin/dbdump --rack [--rack ] /opt/sgi/sbin/dbdump |
Use the --admin argument to dump the system admin controller (admin node)
Use the --leader argument to dump all rack leader controllers (leader nodes)
Use the --rack argument to dump a specific rack
Use the dbdump command without any argument to dump the entire Altix ICE system.
EXAMPLES
Example 5-1. dbdump Command Examples
To dump the entire database, perform the following:
admin:~ # dbdump
0 is { cluster=oscar ifname=service0-bmc dev=bmc0 ip=172.24.0.3 net=head-bmc node=service0
nodetype=oscar_service mac=00:30:48:8e:
1 is { cluster=oscar ifname=service0 dev=eth0 ip=172.23.0.3 net=head node=service0
nodetype=oscar_service mac=00:30:48:33:53:2e }
2 is { cluster=oscar ifname=service0-ib0 dev=ib0 ip=10.148.0.2 net=ib-0 node=service0
nodetype=oscar_service }
3 is { cluster=oscar ifname=service0-ib1 dev=ib1 ip=10.149.0.2 net=ib-1 node=service0
nodetype=oscar_service }
4 is { cluster=oscar dev=eth0 ip=128.162.244.86 net=public node=oscar_server
nodetype=oscar_server mac=00:30:48:34:2B:E0 }
... |
| Note: Some of the sample output in this section has been modified to fit the format of this manual. |
To dump just the rack leader controller, perform the following:
admin:~ # /opt/sgi/sbin/dbdump --leader
0 is { cluster=rack1 ifname=r1lead-bmc dev=bmc0 ip=172.24.0.2 net=head-bmc node=r1lead
nodetype=oscar_leader mac=00:30:48:8a:a4:c2 }
1 is { cluster=rack1 ifname=lead-bmc dev=eth0 ip=192.168.160.1 net=bmc node=r1lead
nodetype=oscar_leader mac=00:30:48:33:54:9e }
2 is { cluster=rack1 ifname=lead-eth dev=eth0 ip=192.168.159.1 net=gbe node=r1lead
nodetype=oscar_leader mac=00:30:48:33:54:9e }
3 is { cluster=rack1 ifname=r1lead dev=eth0 ip=172.23.0.2 net=head node=r1lead
nodetype=oscar_leader mac=00:30:48:33:54:9e }
4 is { cluster=rack1 ifname=r1lead-ib0 dev=ib0 ip=10.148.0.1 net=ib-0 node=r1lead
nodetype=oscar_leader }
5 is { cluster=rack1 ifname=r1lead-ib1 dev=ib1 ip=10.149.0.1 net=ib-1 node=r1lead
nodetype=oscar_leader } |
To dump just one rack, perform the following:
admin:~ # /opt/sgi/sbin/dbdump --rack 1
0 is { cluster=rack1 ifname=i0n0-bmc dev=bmc0 ip=192.168.160.10 net=bmc node=r1i0n0
nodetype=oscar_clients mac=00:30:48:7a:a7:96 }
1 is { cluster=rack1 ifname=i0n0-eth dev=eth0 ip=192.168.159.10 net=gbe node=r1i0n0
nodetype=oscar_clients mac=00:30:48:7a:a7:94 }
2 is { cluster=rack1 ifname=r1i0n0-ib0 dev=ib0 ip=10.148.0.3 net=ib-0 node=r1i0n0
nodetype=oscar_clients }
3 is { cluster=rack1 ifname=r1i0n0-ib1 dev=ib1 ip=10.149.0.3 net=ib-1 node=r1i0n0
nodetype=oscar_clients }
4 is { cluster=rack1 ifname=i0n1-bmc dev=bmc0 ip=192.168.160.11 net=bmc node=r1i0n1
nodetype=oscar_clients mac=00:30:48:7a:a7:86 slot=1 }
5 is { cluster=rack1 ifname=i0n1-eth dev=eth0 ip=192.168.159.11 net=gbe node=r1i0n1
nodetype=oscar_clients mac=00:30:48:7a:a7:84 slot=1 }
6 is { cluster=rack1 ifname=r1i0n1-ib0 dev=ib0 ip=10.148.0.4 net=ib-0 node=r1i0n1
nodetype=oscar_clients slot=1 }
7 is { cluster=rack1 ifname=r1i0n1-ib1 dev=ib1 ip=10.149.0.4 net=ib-1 node=r1i0n1
nodetype=oscar_clients slot=1 }
8 is { cluster=rack1 ifname=i0n10-bmc dev=bmc0 ip=192.168.160.20 net=bmc node=r1i0n10
nodetype=oscar_clients slot=10 }
9 is { cluster=rack1 ifname=i0n10-eth dev=eth0 ip=192.168.159.20 net=gbe node=r1i0n10
nodetype=oscar_clients slot=10 }
10 is { cluster=rack1 ifname=r1i0n10-ib0 dev=ib0 ip=10.148.0.13 net=ib-0 node=r1i0n10
nodetype=oscar_clients slot=10 }
... |
The smc-info-gather command enables to collect vital system data especially when troubleshooting problems. The smc-info-gather command collects the information about the following:
Digital media dminfo files, syslogs, Dynamic Host Configuration Protocol (DHCP), network file system (NFS)
MySQL cluster database dump
Network service configuration files, for example, C3, Ganglia, DHCP, domain name service (DNS) configuration files
A list of installed system images
Log files in /var/log/messages
Chassis management control (CMC) slot table for each rack
basic input-output system (BIOS), Baseboard Management Controller (BMC), CMC and InfiniBand fabric software versions from all Altix ICE nodes
To see a usage statement for the smc-info-gather command, perform the following:
admin:/opt/sgi/sbin # smc-info-gather -h
usage: smc-info-gather [-h] [-P path] [-o file]
smc-info-gather -h # Print this usage page
smc-info-gather -o file # Tar and gzip the directories
into file (imply -n)
smc-info-gather -p path # Directory to write the data
(default /var/tmp/smc)
|
The cminfo command is used internally by many of the SMC for Altix ICE scripts that are used to discover, configure, and manage an SGI Altix ICE system.
In a troubleshooting situation, you can use it to gather information about your system. To see a usage statement from a rack leader controller, perform the following:
r1lead:~ # cminfo --help Usage: cminfo [--bmc_base_ip|--bmc_ifname|--bmc_iftype|--bmc_ip|--bmc_mac|--bmc_netmask|--bmc_nic| --dns_domain|--gbe_base_i p|--gbe_ifname|--gbe_iftype|--gbe_ip|--gbe_mac|--gbe_netmask|--gbe_nic|--head_base_ip| --head_bmc_base_ip|--head_bmc_ifname| --head_bmc_iftype|--head_bmc_ip|--head_bmc_mac|--head_bmc_netmask|--head_bmc_nic|--head_ifname| --head_iftype|--head_ip|--he ad_mac|--head_netmask|--head_nic|--ib_0_base_ip|--ib_0_ifname|--ib_0_iftype|--ib_0_ip|--ib_0_mac| --ib_0_netmask|--ib_0_nic| --ib_1_base_ip|--ib_1_ifname|--ib_1_iftype|--ib_1_ip|--ib_1_mac|--ib_1_netmask| --ib_1_nic|--name|--rack] r1lead:~ # cminfo --bmc_base_ip |
EXAMPLES
Example 5-2. cminfo Command Examples
To see the rack leader node BMC IP address, perform the following:
r1lead:~ # cminfo --bmc_base_ip 192.168.160.0 |
To see the rack leader DNS domain, perform the following:
r1lead:~ # cminfo --dns_domain ice.domain_name.mycompany.com |
To see the BMC nic, perform the following:
r1lead:~ # cminfo --bmc_nic eth0 |
To see the IP address of the ib1 InfiniBand fabric, perform the following:
r1lead:~ # cminfo --ib_1_base_ip 10.149.0.0 |
The kdump utility is a kexec-based crash dumping mechanism for the Linux operating system. You can downlonad debuginfo kernel RPMs for use with crash and any kernel dumps at the following location: http://support.novell.com/linux/psdb/byproduct.html.
To get a traceback or system dump, perform the following from the system console:
console r1i0n0 ^e c l 1 8 ^e c l 1 t #traceback ^e c l 1 c #dump |
| Note: This example shows the letter “c”, a lowercase L “l”, and the number one “ 1” in all three lines. |
On the admin node, go to /net/r1lead/var/log/consoles for the traceback and /net/r1lead/var/log/dumps/r1i0n0 for the system dump.
You can dump a compute node, the rack leader, such as, r1lead, or a service node, such as, service0.
| Note: Your SGI Altix ICE system comes preinstalled with the appropriate firmware. See your SGI field support person for any BMC, BIOS, and CMC firmware updates. |
The SGI Altix ICE system firmware software consists of the following components:
| sgi-ice-blade-bmc-1.43.5-1.x86_64.rpm | |
Blade BMC firmware and update tool | |
| sgi-ice-blade-bios-2007.08.10-1.x86_64.rpm | |
Blade BIOS image and update tool | |
| sgi-ice-cmc-0.0.11-2.x86_64.rpm | |
CMC firmware and update tool | |
To identify the BIOS you need both the version and the release date. You can get these using the dmidecode command. Log onto the node on which you want to interrogate BIOS level and perform the following:
# dmidecode -s bios-version; dmidecode -s bios-release-date |
The BMC firmware revision can be retrieved using the ipmiwrapper . For example, from the admin node, the following command gets the BMC firmware revision for r1i0n0:
# ipmiwrapper r1i0n0 bmc info | grep 'Firmware Revision' |
The CMC firmware version can can be retrieved using the version command to the CMC. For example, if you are logged onto the r1lead rack leader controller, the following command gets the CMC firmware version:
# ssh root@r1i0-cmc version |
The ibstat command retrieves information for the InfiniBand links including the firmware version. The following command gets the InfiniBand firmware version:
# ibstat | grep Firmware |
The firmware_revs script on the system admin controller (admin node) collects the firmware information for all nodes in the SGI Altix ICE system, as follows:
admin:~ # firmware_revs BIOS versions: -------------- admin: 6.00 r1lead: 6.00 service0: 6.00 r1i0n0: 6.00 r1i0n1: 6.00 r1i0n8: 6.00 r1i1n0: 6.00 r1i1n1: 6.00 r1i1n8: 6.00 BIOS release dates: ------------------- admin: 05/10/2007 r1lead: 05/10/2007 service0: 05/10/2007 r1i0n0: 05/29/2007 r1i0n1: 05/29/2007 r1i0n8: 05/29/2007 r1i1n0: 05/29/2007 r1i1n1: 05/29/2007 r1i1n8: 05/29/2007 BMC versions: ------------- admin: 1.31 r1lead: 1.31 service0: 1.31 r1i0n0: 1.29 r1i0n1: 1.29 r1i0n8: 1.29 r1i1n0: 1.29 r1i1n1: 1.29 r1i1n8: 1.29 CMC versions: ------------- r1i0c: 0.0.9pre10 r1i1c: 0.0.9pre10 Infiniband versions: -------------------- r1lead: 4.7.600 service0: 4.7.600 r1i0n0: 1.2.0 r1i0n0: 1.2.0 r1i0n1: 1.2.0 r1i0n1: 1.2.0 r1i0n8: 1.2.0 r1i0n8: 1.2.0 r1i1n0: 1.2.0 r1i1n0: 1.2.0 r1i1n1: 1.2.0 r1i1n1: 1.2.0 r1i1n8: 1.2.0 r1i1n8: 1.2.0 |